Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
ICML 2025
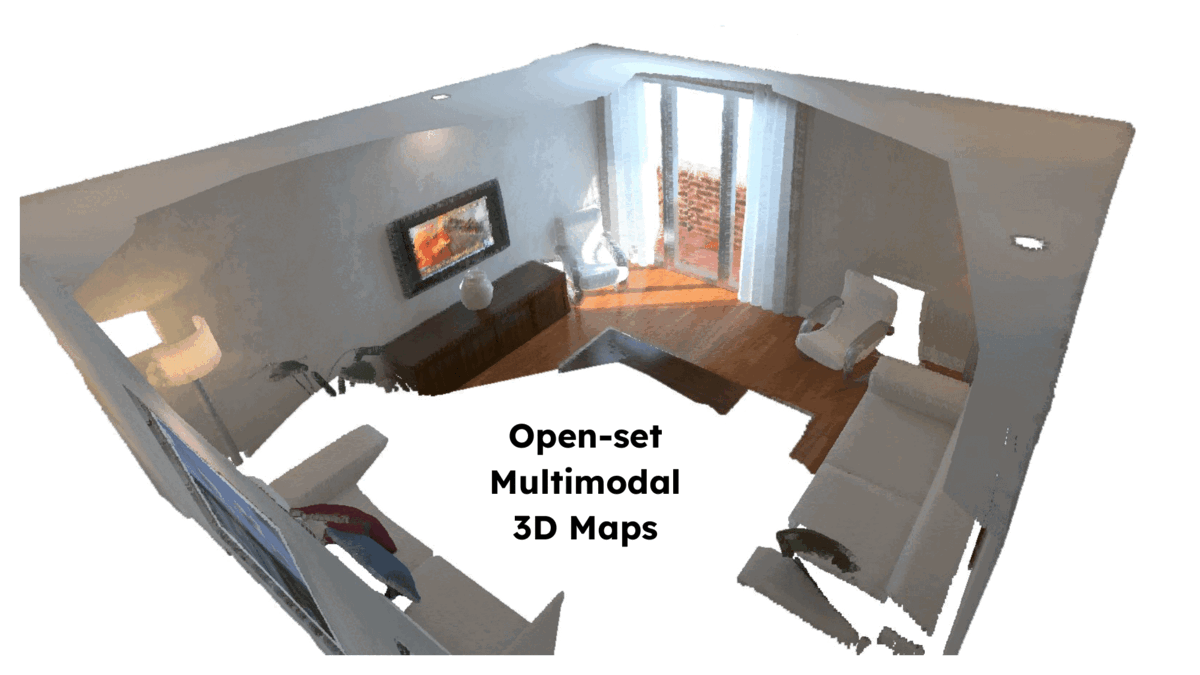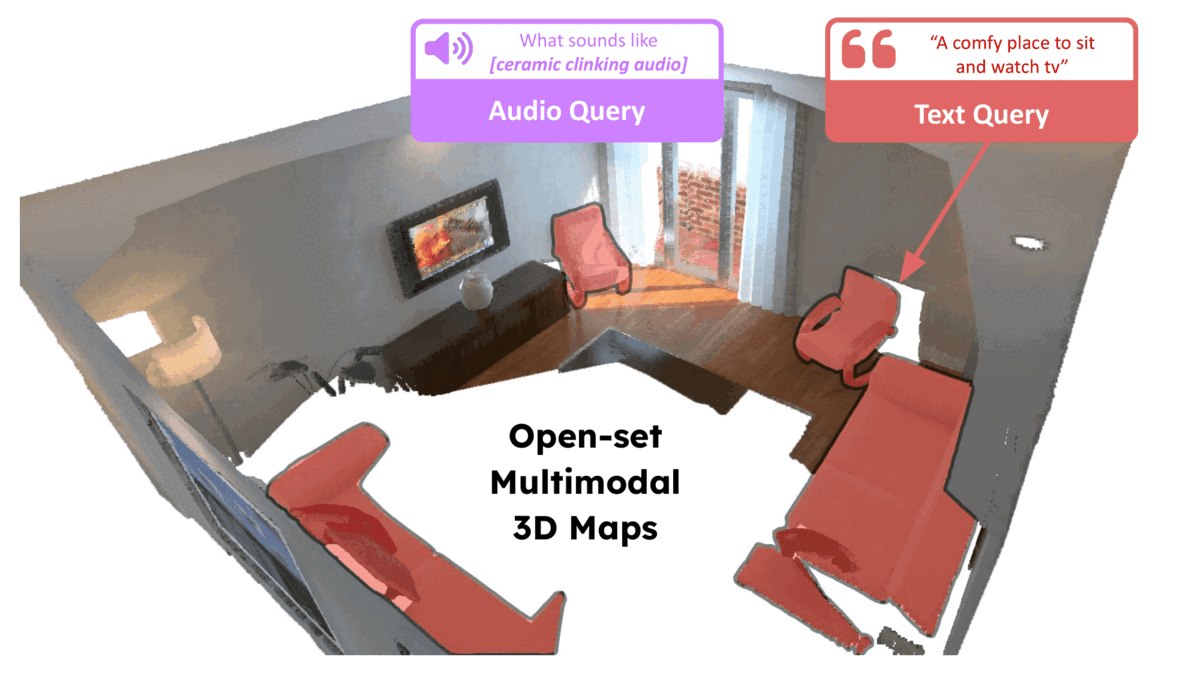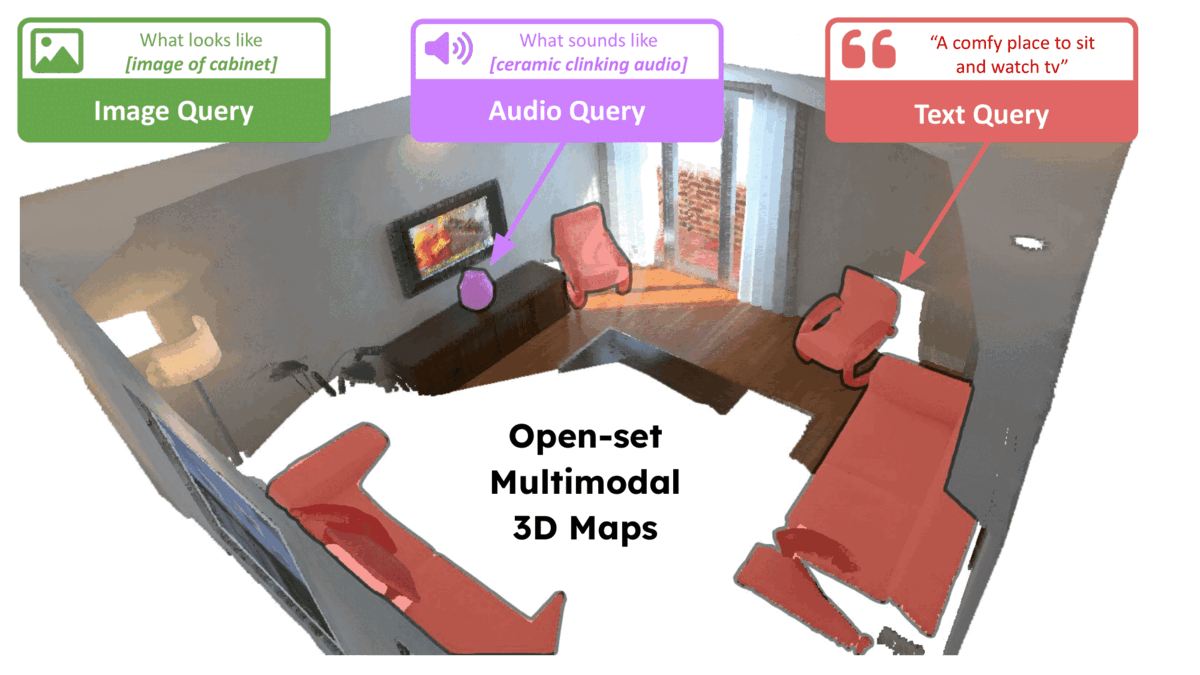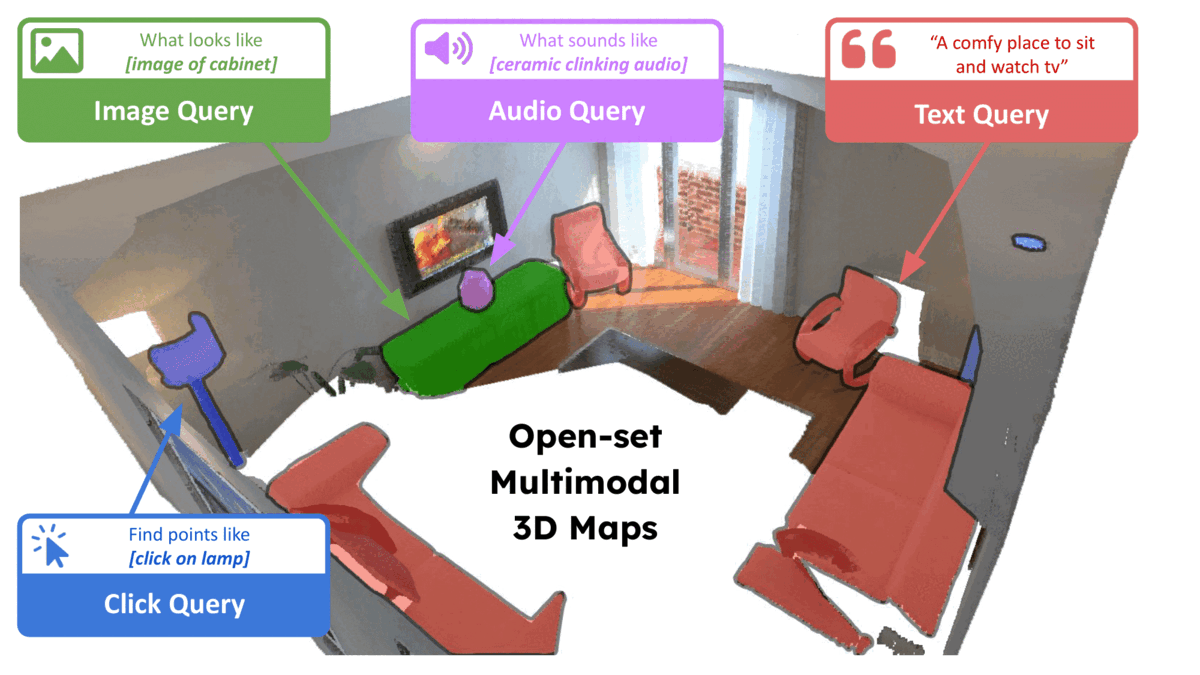
We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
I worked on the data preprocessing stage of Locate 3D.
@inproceedings{locate3d,
title = {Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D},
author = {Arnaud, Sergio and McVay, Paul and Martin, Ada and Majumdar, Arjun and Jatavallabhula, {Krishna Murthy} and Thomas, Phillip and Partsey, Ruslan and Dugas, Daniel and Gejji, Abha and Sax, Alexander and Berges, Vincent-Pierre and Henaff, Mikael and Jain, Ayush and Cao, Ang and Prasad, Ishita and Kalakrishnan, Mrinal and Rabbat, Michael and Ballas, Nicolas and Assran, Mido and Maksymets, Oleksandr and Rajeswaran, Aravind and Meier, Franziska},
year = {2025},
booktitle = {ICML},
}