publications
For a list of my featured publications, please scroll down the home page. For an exhaustive list that includes workshop papers, please see my CV.
* indicates that authors contributed equally
Indicates featured/representative publications
2025
-
 Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3DSergio Arnaud, Paul McVay, Ada Martin, Arjun Majumdar, Krishna Murthy Jatavallabhula, Phillip Thomas, Ruslan Partsey, Daniel Dugas, Abha Gejji, Alexander Sax, Vincent-Pierre Berges, Mikael Henaff, Ayush Jain, Ang Cao, Ishita Prasad, Mrinal Kalakrishnan, Michael Rabbat, Nicolas Ballas, Mido Assran, Oleksandr Maksymets, Aravind Rajeswaran, and Franziska MeierICML 2025
Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3DSergio Arnaud, Paul McVay, Ada Martin, Arjun Majumdar, Krishna Murthy Jatavallabhula, Phillip Thomas, Ruslan Partsey, Daniel Dugas, Abha Gejji, Alexander Sax, Vincent-Pierre Berges, Mikael Henaff, Ayush Jain, Ang Cao, Ishita Prasad, Mrinal Kalakrishnan, Michael Rabbat, Nicolas Ballas, Mido Assran, Oleksandr Maksymets, Aravind Rajeswaran, and Franziska MeierICML 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
I worked on the data preprocessing stage of Locate 3D.
@inproceedings{locate3d, title = {Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D}, author = {Arnaud, Sergio and McVay, Paul and Martin, Ada and Majumdar, Arjun and Jatavallabhula, {Krishna Murthy} and Thomas, Phillip and Partsey, Ruslan and Dugas, Daniel and Gejji, Abha and Sax, Alexander and Berges, Vincent-Pierre and Henaff, Mikael and Jain, Ayush and Cao, Ang and Prasad, Ishita and Kalakrishnan, Mrinal and Rabbat, Michael and Ballas, Nicolas and Assran, Mido and Maksymets, Oleksandr and Rajeswaran, Aravind and Meier, Franziska}, year = {2025}, booktitle = {ICML}, } -
 Gaussian Splatting Visual MPC for Granular Media ManipulationWei-Cheng Tseng, Ellina Zhang, Krishna Murthy Jatavallabhula, and Florian ShkurtiICRA 2025
Gaussian Splatting Visual MPC for Granular Media ManipulationWei-Cheng Tseng, Ellina Zhang, Krishna Murthy Jatavallabhula, and Florian ShkurtiICRA 2025Recent advancements in learned 3D representations have enabled significant progress in solving complex robotic manipulation tasks, particularly for rigid-body objects. However, manipulating granular materials such as beans, nuts, and rice, remains challenging due to the intricate physics of particle interactions, high-dimensional and partially observable state, inability to visually track individual particles in a pile, and the computational demands of accurate dynamics prediction. Current deep latent dynamics models often struggle to generalize in granular material manipulation due to a lack of inductive biases. In this work, we propose a novel approach that learns a visual dynamics model over Gaussian splatting representations of scenes and leverages this model for manipulating granular media via Model-Predictive Control. Our method enables efficient optimization for complex manipulation tasks on piles of granular media. We evaluate our approach in both simulated and real-world settings, demonstrating its ability to solve unseen planning tasks and generalize to new environments in a zero-shot transfer. We also show significant prediction and manipulation performance improvements compared to existing granular media manipulation methods.
I co-advised Wei-Cheng on this project.
@inproceedings{gs-mpc, title = {Gaussian Splatting Visual MPC for Granular Media Manipulation}, author = {Tseng, Wei-Cheng and Zhang, Ellina and Jatavallabhula, {Krishna Murthy} and Shkurti, Florian}, year = {2025}, booktitle = {ICRA}, }
2024
-
 SplaTAM:Splat, Track, and Map 3D Gaussians for Dense RGB-D SLAMNikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, and Jonathon LuitenCVPR 2024
SplaTAM:Splat, Track, and Map 3D Gaussians for Dense RGB-D SLAMNikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, and Jonathon LuitenCVPR 2024Dense simultaneous localization and mapping (SLAM) is pivotal for embodied scene understanding. Recent work has shown that 3D Gaussians enable high-quality reconstruction and real-time rendering of scenes using multiple posed cameras. In this light, we show for the first time that representing a scene by a 3D Gaussian Splatting radiance field can enable dense SLAM using a single unposed monocular RGB-D camera. Our method, SplaTAM, addresses the limitations of prior radiance field-based representations, including fast rendering and optimization, the ability to determine if areas have been previously mapped, and structured map expansion by adding more Gaussians. In particular, we employ an online tracking and mapping pipeline while tailoring it to specifically use an underlying Gaussian representation and silhouette-guided optimization via differentiable rendering. Extensive experiments on simulated and real-world data show that SplaTAM achieves up to 2 X state-of-the-art performance in camera pose estimation, map construction, and novel-view synthesis, demonstrating its superiority over existing approaches.
This project was spearheaded by Nikhil and Jonathon. I interfaced Gaussian Splatting with GradSLAM, and provided SLAM-specific guidance over the course of the project.
@inproceedings{splatam, title = {SplaTAM:Splat, Track, and Map 3D Gaussians for Dense RGB-D SLAM}, author = {Keetha, Nikhil and Karhade, Jay and Jatavallabhula, {Krishna Murthy} and Yang, Gengshan and Scherer, Sebastian and Ramanan, Deva and Luiten, Jonathon}, year = {2024}, booktitle = {CVPR}, } -

ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
Qiao Gu*, Alihusein Kuwajerwala*, Sacha Morin*, Krishna Murthy Jatavallabhula*, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, Chuang Gan, Celso Miguel de Melo, Joshua B. Tenenbaum, Antonio Torralba, Florian Shkurti, and Liam PaullICRA 2024For robots to perform a wide variety of tasks, they require a 3D representation of the world that is semantically rich, yet compact and efficient for task-driven perception and planning. Recent approaches have attempted to leverage features from large vision-language models to encode semantics in 3D representations. However, these approaches tend to produce maps with per-point feature vectors, which do not scale well in larger environments, nor do they contain semantic spatial relationships between entities in the environment, which are useful for downstream planning. In this work, we propose ConceptGraphs, an open-vocabulary graph-structured representation for 3D scenes. ConceptGraphs is built by leveraging 2D foundation models and fusing their output to 3D by multi-view association. The resulting representations generalize to novel semantic classes, without the need to collect large 3D datasets or finetune models. We demonstrate the utility of this representation through a number of downstream planning tasks that are specified through abstract (language) prompts and require complex reasoning over spatial and semantic concepts.
I co-led multiple aspects of this work, building off of our prior work with ConceptFusion.
@inproceedings{conceptgraphs, title = {ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning}, author = {Gu, Qiao and Kuwajerwala, Alihusein and Morin, Sacha and Jatavallabhula, {Krishna Murthy} and Sen, Bipasha and Agarwal, Aditya and Rivera, Corban and Paul, William and Ellis, Kirsty and Chellappa, Rama and Gan, Chuang and {de Melo}, {Celso Miguel} and Tenenbaum, {Joshua B.} and Torralba, Antonio and Shkurti, Florian and Paull, Liam}, year = {2024}, booktitle = {ICRA}, featured = {true} } -
 iML: Efficient 3D Instance Mapping and LocalizationGeorge Tang, Antonio Torralba, and Krishna Murthy JatavallabhulaICRA 2024
iML: Efficient 3D Instance Mapping and LocalizationGeorge Tang, Antonio Torralba, and Krishna Murthy JatavallabhulaICRA 2024@inproceedings{iml, title = {iML: Efficient 3D Instance Mapping and Localization}, author = {Tang, George and Torralba, Antonio and Jatavallabhula, {Krishna Murthy}}, year = {2024}, booktitle = {ICRA}, } -
 Tactile Estimation of Extrinsic Contact Patch for Stable PlacementICRA 2024
Tactile Estimation of Extrinsic Contact Patch for Stable PlacementICRA 2024Precise perception of contact interactions is essential for the fine-grained manipulation skills for robots. In this paper, we present the design of feedback skills for robots that must learn to stack complex-shaped objects on top of each other. To design such a system, a robot should be able to reason about the stability of placement from very gentle contact interactions. Our results demonstrate that it is possible to infer the stability of object placement based on tactile readings during contact formation between the object and its environment. In particular, we estimate the contact patch between a grasped object and its environment using force and tactile observations to estimate the stability of the object during a contact formation. The contact patch could be used to estimate the stability of the object upon the release of the grasp. The proposed method is demonstrated on various pairs of objects that are used in a very popular board game.
Kei and Devesh did much of the work. I was consulted for advice with tactile sensors and problem framing.
@inproceedings{tactile-placement, title = {Tactile Estimation of Extrinsic Contact Patch for Stable Placement}, author = {Ota, Kei and Jha, Devesh and Jatavallabhula, {Krishna Murthy} and Kanezaki, Asako and Tenenbaum, {Joshua B.}}, year = {2024}, booktitle = {ICRA}, } -
 Talk2BEV: Language-enhanced Bird’s-eye View Maps for Autonomous DrivingVikrant Dewangan, Tushar Choudhary*, Shivam Chandhok*, Shubham Priyadarshan, Anushka Jain, Arun Singh, Siddharth Srivastava, Krishna Murthy Jatavallabhula*, and Madhava KrishnaICRA 2024
Talk2BEV: Language-enhanced Bird’s-eye View Maps for Autonomous DrivingVikrant Dewangan, Tushar Choudhary*, Shivam Chandhok*, Shubham Priyadarshan, Anushka Jain, Arun Singh, Siddharth Srivastava, Krishna Murthy Jatavallabhula*, and Madhava KrishnaICRA 2024This work introduces Talk2BEV, a large vision-language model (LVLM) interface for bird’s-eye view (BEV) maps commonly used in autonomous driving. While existing perception systems for autonomous driving scenarios have largely focused on a pre-defined (closed) set of object categories and driving scenarios, Talk2BEV eliminates the need for BEV-specific training, relying instead on performant pre-trained LVLMs. This enables a single system to cater to a variety of autonomous driving tasks encompassing visual and spatial reasoning, predicting the intents of traffic actors, and decision-making based on visual cues. We extensively evaluate Talk2BEV n a large number of scene understanding tasks that rely on both the ability to interpret freefrom natural language queries, and in grounding these queries to the visual context embedded into the language-enhanced BEV map. To enable further research in LVLMs for autonomous driving scenarios, we develop and release Talk2BEV-Bench, a benchmark encompassing 1000 human-annotated BEV scenarios, with more than 20,000 questions and ground-truth responses from the NuScenes dataset.
I conceived the initial idea and played a lead-advisor role on the project.
@inproceedings{talk2bev, title = {Talk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving}, author = {Dewangan, Vikrant and Choudhary, Tushar and Chandhok, Shivam and Priyadarshan, Shubham and Jain, Anushka and Singh, Arun and Srivastava, Siddharth and Jatavallabhula, {Krishna Murthy} and Krishna, Madhava}, year = {2024}, booktitle = {ICRA}, } -
 Anticipate & Act: Integrating LLMs and Classical Planning for Efficient Task Execution in Household EnvironmentsRaghav Arora, Shivam Singh, Karthik Swaminathan, Ahana Datta, Snehasis Banerjee, Brojeshwar Bhowmick, Krishna Murthy Jatavallabhula, Mohan Sridharan, and Madhava KrishnaICRA 2024
Anticipate & Act: Integrating LLMs and Classical Planning for Efficient Task Execution in Household EnvironmentsRaghav Arora, Shivam Singh, Karthik Swaminathan, Ahana Datta, Snehasis Banerjee, Brojeshwar Bhowmick, Krishna Murthy Jatavallabhula, Mohan Sridharan, and Madhava KrishnaICRA 2024Assistive agents performing household tasks such as making the bed, preparing coffee, or cooking breakfast, often consider one task at a time by computing a plan of actions that accomplishes this task. The agents can be more efficient by anticipating upcoming tasks, and computing and executing an action sequence that jointly achieves these tasks. State of the art methods for task anticipating use data-driven deep network architectures and Large Language Models (LLMs) for task estimation but they do so at the level of high-level tasks and/or require a large number of training examples. Our framework leverages the generic knowledge of LLMs through a small number of prompts to perform high-level task anticipation, using the anticipated tasks as joint goals in a classical planning system to compute a sequence of finer-granularity actions that jointly achieve these goals. We ground and evaluate our framework’s capabilities in realistic simulated scenarios in the VirtualHome environment and demonstrate a 31 percent reduction in the execution time in comparison with a system that does not consider upcoming tasks.
I closely mentored the students on this project, including conceptualizing the broad theme and advising on experiment design. Raghav and Shivam did nearly all of the work. Mohan wrote a bulk of the manuscript.
@inproceedings{task-anticipation, title = {Anticipate & Act: Integrating LLMs and Classical Planning for Efficient Task Execution in Household Environments}, author = {Arora, Raghav and Singh, Shivam and Swaminathan, Karthik and Datta, Ahana and Banerjee, Snehasis and Bhowmick, Brojeshwar and Jatavallabhula, {Krishna Murthy} and Sridharan, Mohan and Krishna, Madhava}, year = {2024}, booktitle = {ICRA}, } -
 Follow Anything: Open-set detection, tracking, and following in real-timeAlaa Maalouf, Ninad Jadhav, Krishna Murthy Jatavallabhula, Makram Chahine, Daniel M Vogt, Robert J Wood, Antonio Torralba, and Daniela RusRobotics and Automation Letters 2024
Follow Anything: Open-set detection, tracking, and following in real-timeAlaa Maalouf, Ninad Jadhav, Krishna Murthy Jatavallabhula, Makram Chahine, Daniel M Vogt, Robert J Wood, Antonio Torralba, and Daniela RusRobotics and Automation Letters 2024Tracking and following objects of interest is critical to several robotics use cases, ranging from industrial automation to logistics and warehousing, to healthcare and security. In this paper, we present a robotic system to detect, track, and follow any object in real-time. Our approach, dubbed “follow anything” (FAn), is an open-vocabulary and multimodal model – it is not restricted to concepts seen at training time and can be applied to novel classes at inference time using text, images, or click queries. Leveraging rich visual descriptors from large-scale pre-trained models (foundation models), FAn can detect and segment objects by matching multimodal queries (text, images, clicks) against an input image sequence. These detected and segmented objects are tracked across image frames, all while accounting for occlusion and object re-emergence. We demonstrate FAn on a real-world robotic system (a micro aerial vehicle) and report its ability to seamlessly follow the objects of interest in a real-time control loop. FAn can be deployed on a laptop with a lightweight (6-8 GB) graphics card, achieving a throughput of 6-20 frames per second.
Alaa and Ninad did most of the work. I was consulted primarily for systems building advice.
@inproceedings{fam, title = {Follow Anything: Open-set detection, tracking, and following in real-time}, author = {Maalouf, Alaa and Jadhav, Ninad and Jatavallabhula, {Krishna Murthy} and Chahine, Makram and Vogt, {Daniel M} and Wood, {Robert J} and Torralba, Antonio and Rus, Daniela}, year = {2024}, booktitle = {Robotics and Automation Letters}, }
2023
-

ALT-Pilot: Autonomous navigation with Language augmented Topometric maps
Mohd Omama, Pranav Inani, Pranjal Paul, Sarat Chandra Yellapragada, Krishna Murthy Jatavallabhula*, Sandeep Chinchali*, and Madhava Krishnapreprint 2023We present an autonomous navigation system that operates without assuming HD LiDAR maps of the environment. Our system, ALT-Pilot, relies only on publicly available road network information and a sparse (and noisy) set of crowdsourced language landmarks. With the help of onboard sensors and a language-augmented topometric map, ALT-Pilot autonomously pilots the vehicle to any destination on the road network. We achieve this by leveraging vision- language models pre-trained on web-scale data to identify potential landmarks in a scene, incorporating vision-language features into the recursive Bayesian state estimation stack to generate global (route) plans, and a reactive trajectory planner and controller operating in the vehicle frame. We implement and evaluate ALT-Pilot in simulation and on a real, full-scale autonomous vehicle and report improvements over state-of- the-art topometric navigation systems by a factor of 3x on localization accuracy and 5x on goal reachability.
Idea jointly conceived by Omama and me. I established project directions/goals; closely mentored Omama, Pranjal, and Pranav. Omama did bulk of the implementation, with significant contributions also from Pranjal and Pranav.
title = {ALT-Pilot: Autonomous navigation with Language augmented Topometric maps}, author = {Omama, Mohd and Inani, Pranav and Paul, Pranjal and Yellapragada, {Sarat Chandra} and Jatavallabhula, {Krishna Murthy} and Chinchali, Sandeep and Krishna, Madhava}, year = {2023}, booktitle = {preprint}, featured = {true}, } -
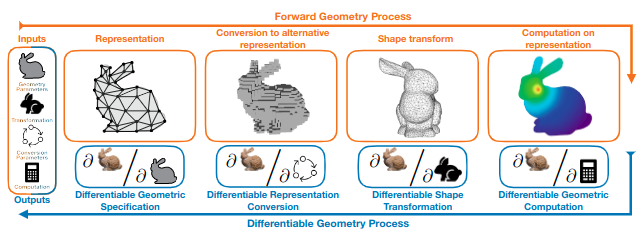 Differentiable Visual Computing for Inverse Problems and Machine LearningAndrew Spielberg, Cengiz Oztireli, Derek Nowrouzezahrai, Fangcheng Zhong, Konstantinos Rematas, Krishna Murthy Jatavallabhula, and Tzu-Mao LiNature Machine Intelligence 2023
Differentiable Visual Computing for Inverse Problems and Machine LearningAndrew Spielberg, Cengiz Oztireli, Derek Nowrouzezahrai, Fangcheng Zhong, Konstantinos Rematas, Krishna Murthy Jatavallabhula, and Tzu-Mao LiNature Machine Intelligence 2023Modern 3D computer graphics technologies are able to reproduce the dynamics and appearance of real world environments and phenomena, building atop theoretical models in applied mathematics, statistics, and physics. These methods are applied in architectural design and visualization, biological imaging, and visual effects. Differentiable methods, instead, aim to determine how graphics outputs (i.e., the real world dynamics or appearance) change when the environment changes. We survey this growing body of work and propose a holistic and unified differentiable visual computing pipeline. Differentiable visual computing can be leveraged to efficiently solve otherwise intractable problems in physical inference, optimal control, object detection and scene understanding, computational design, manufacturing, autonomous vehicles, and robotics. Any application that can benefit from an understanding of the underlying dynamics of the real world stands to benefit significantly from a differentiable graphics treatment. We draw parallels between the well-established computer graphics pipeline and a unified differentiable graphics pipeline, targeting consumers, practitioners and researchers. The breadth of fields that these pipelines draws upon — and are of interest to — includes the physical sciences, data sciences, vision and graphics, machine learning, and adjacent mathematical and computing communities.
Andy led this work. Derek was the lead PI.
@inproceedings{diff-visual-computing-review, title = {Differentiable Visual Computing for Inverse Problems and Machine Learning}, author = {Spielberg, Andrew and Oztireli, Cengiz and Nowrouzezahrai, Derek and Zhong, Fangcheng and Rematas, Konstantinos and Jatavallabhula, {Krishna Murthy} and Li, Tzu-Mao}, year = {2023}, booktitle = {Nature Machine Intelligence}, } -
 AnyLoc: Towards Universal Visual Place RecognitionNikhil Keetha*, Avneesh Mishra*, Jay Karhade*, Krishna Murthy Jatavallabhula, Sebastian Scherer, Madhava Krishna, and Sourav GargRobotics and Automation Letters (and ICRA 2024) 2023
AnyLoc: Towards Universal Visual Place RecognitionNikhil Keetha*, Avneesh Mishra*, Jay Karhade*, Krishna Murthy Jatavallabhula, Sebastian Scherer, Madhava Krishna, and Sourav GargRobotics and Automation Letters (and ICRA 2024) 2023VPR is vital for robot localization. To date, the most performant VPR approaches are environment- and task-specific: while they exhibit strong performance in structured environments (predominantly urban driving), their performance degrades severely in unstructured environments, rendering most approaches brittle to robust realworld deployment. In this work, we develop a universal solution to VPR – a technique that works across a broad range of structured and unstructured environments (urban, outdoors, indoors, aerial, underwater, and subterranean environments) without any re-training or finetuning. We demonstrate that general-purpose feature representations derived from off-theshelf self-supervised models with no VPR-specific training are the right substrate upon which to build such a universal VPR solution. Combining these derived features with unsupervised feature aggregation enables our suite of methods, AnyLoc, to achieve up to 4× significantly higher performance than existing approaches. We further obtain a 6 percent improvement in performance by characterizing the semantic properties of these features, uncovering unique domains which encapsulate datasets from similar environments. Our detailed experiments and analysis lay a foundation for building VPR solutions that may be deployed anywhere, anytime, and across anyview.
Nikhil, Avneesh, and Jay equally led this work. Sourav and I closely mentored them on this work (Sourav more closely than me).
@inproceedings{anyloc, title = {AnyLoc: Towards Universal Visual Place Recognition}, author = {Keetha, Nikhil and Mishra, Avneesh and Karhade, Jay and Jatavallabhula, {Krishna Murthy} and Scherer, Sebastian and Krishna, Madhava and Garg, Sourav}, year = {2023}, booktitle = {Robotics and Automation Letters (and ICRA 2024)}, } -
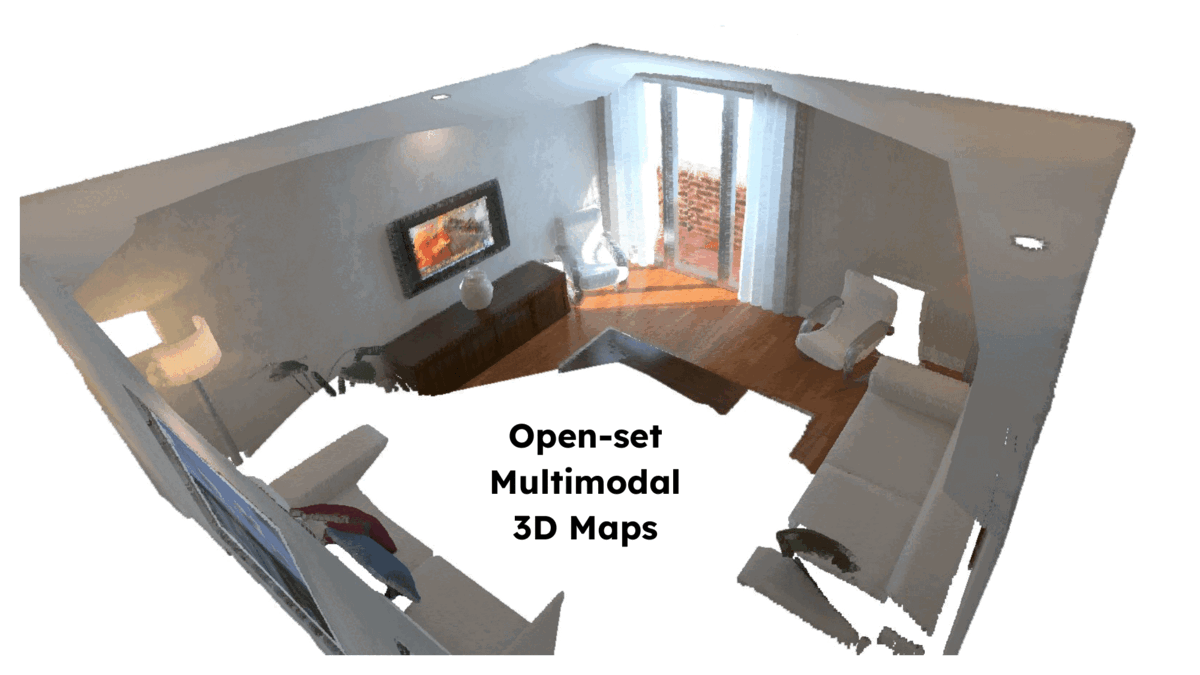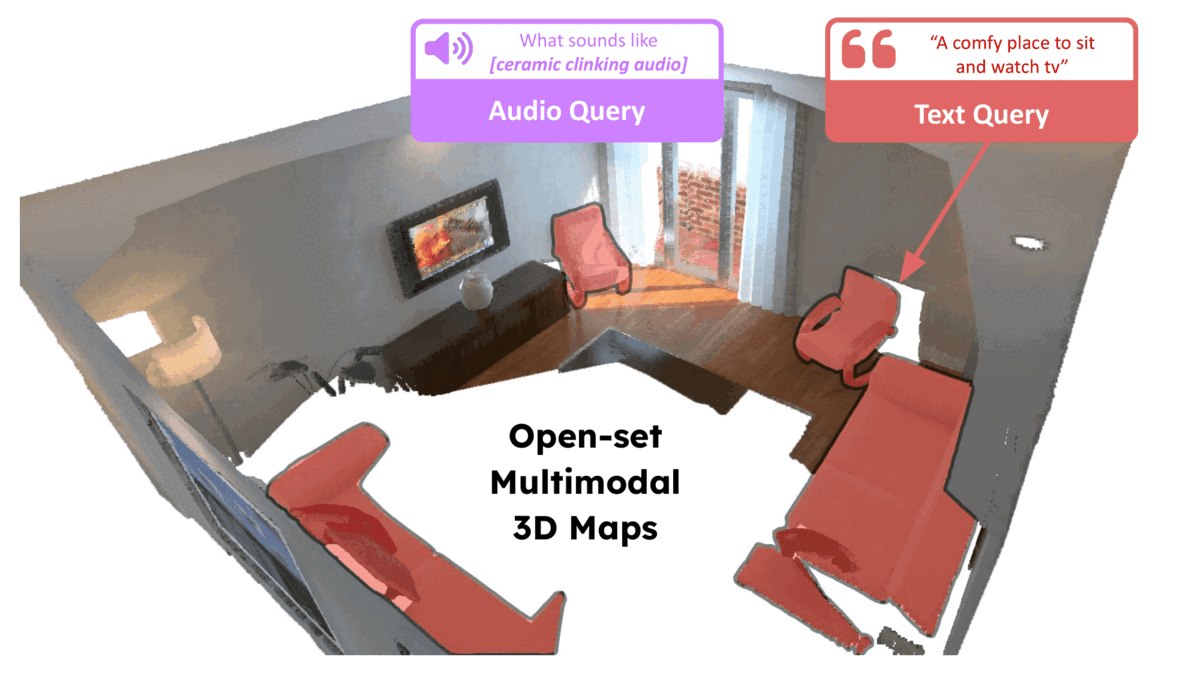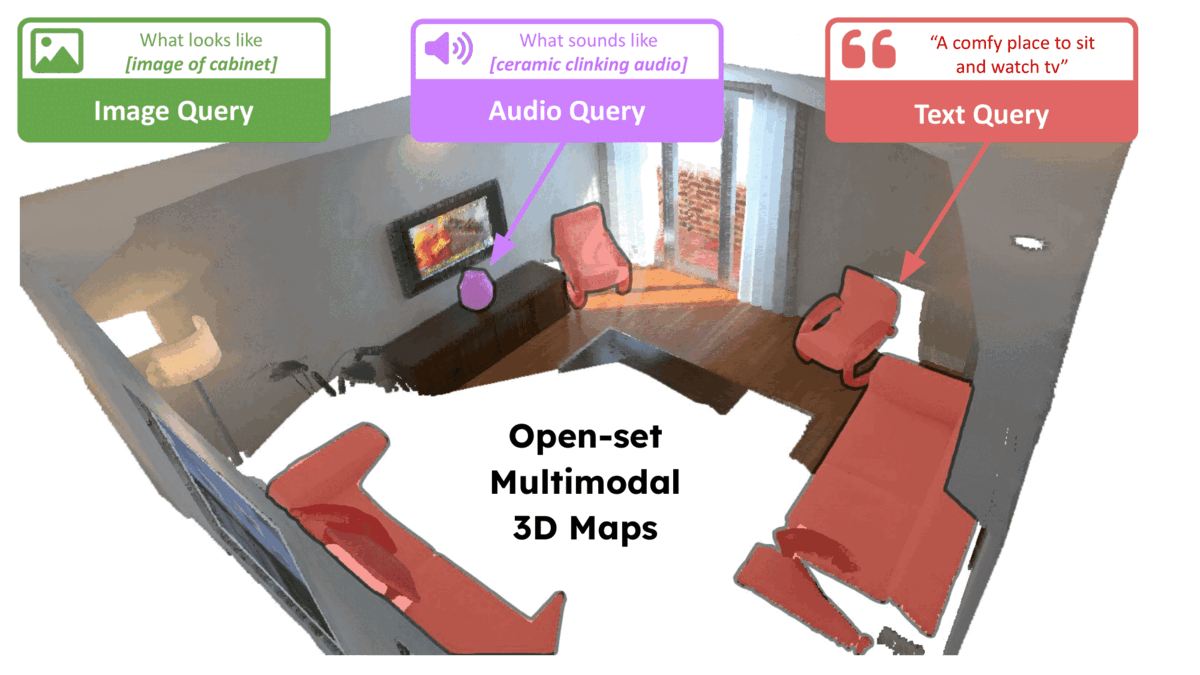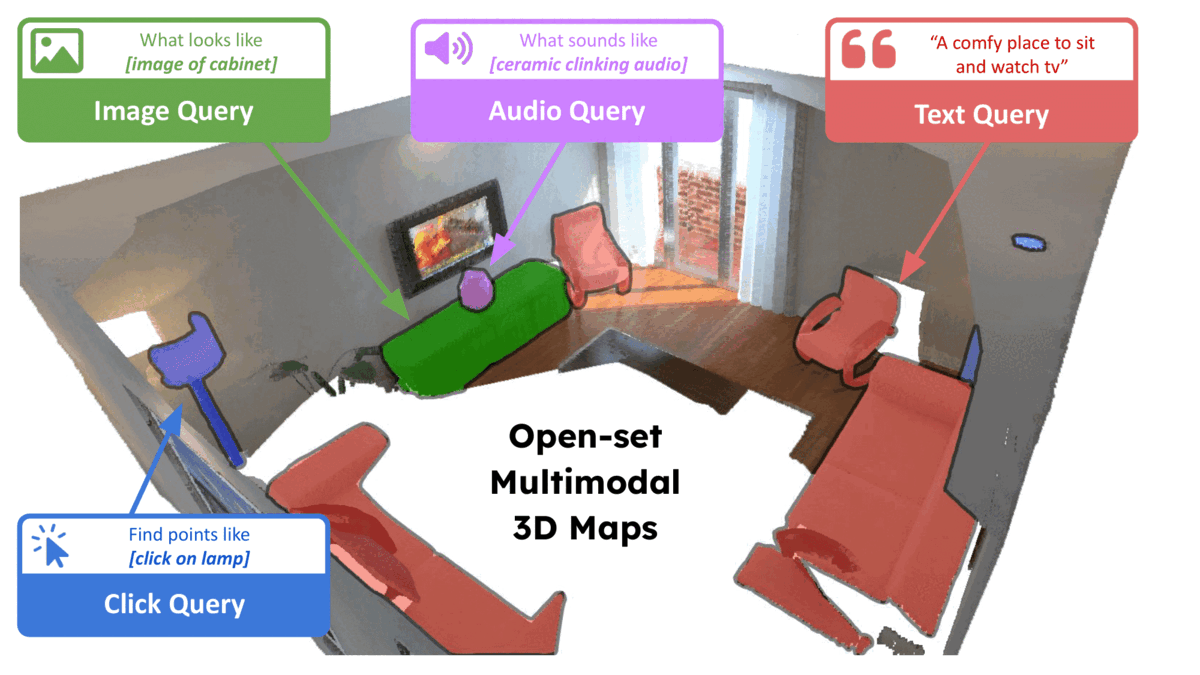
ConceptFusion: Open-set Multimodal 3D Mapping
Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Keetha, Ayush Tewari, Joshua B. Tenenbaum, Celso Miguel de Melo, Madhava Krishna, Liam Paull, Florian Shkurti, and Antonio TorralbaRSS 2023Building 3D maps of the environment is central to robot navigation, planning, and interaction with objects in a scene. Most existing approaches that integrate semantic concepts with 3D maps largely remain confined to the closed-set setting: they can only reason bout a finite set of concepts, pre-defined at training time. Further, these maps can only be queried using class labels, or in recent work, using text prompts. We address both these issues with ConceptFusion, a scene representation that is: (i) fundamentally open-set, enabling reasoning beyond a closed set of concepts (ii) inherently multi-modal, enabling a diverse range of possible queries to the 3D map, from language, to images, to audio, to 3D geometry, all working in concert. ConceptFusion leverages the open-set capabilities of today’s foundation models pre-trained on internet-scale data to reason about concepts across modalities such as natural language, images, and audio. We demonstrate that pixel-aligned open-set features can be fused into 3D maps via traditional SLAM and multi-view fusion approaches. This enables effective zero-shot spatial reasoning, not needing any additional training or finetuning, and retains long-tailed concepts better than supervised approaches, outperforming them by more than 40 percent margin on 3D IoU. We extensively evaluate ConceptFusion on a number of real-world datasets, simulated home environments, a real-world tabletop manipulation task, and an autonomous driving platform. We showcase new avenues for blending foundation models with 3D open-set multimodal mapping.
I conceived the idea and led the project. I also wrote much of the code and the paper. I curated and annotated the UnCoCo dataset and helped with the tabletop robot experiments.
@inproceedings{conceptfusion, title = {ConceptFusion: Open-set Multimodal 3D Mapping}, author = {Jatavallabhula, {Krishna Murthy} and Kuwajerwala, Alihusein and Gu, Qiao and Omama, Mohd and Chen, Tao and Li, Shuang and Iyer, Ganesh and Saryazdi, Soroush and Keetha, Nikhil and Tewari, Ayush and Tenenbaum, {Joshua B.} and {de Melo}, {Celso Miguel} and Krishna, Madhava and Paull, Liam and Shkurti, Florian and Torralba, Antonio}, year = {2023}, booktitle = {RSS}, dataset and helped with the tabletop robot experiments.}, featured = {true} } -
 PAC-NeRF: Physics Augmented Continuum Neural Radiance Fields for Geometry-Agnostic System IdentificationXuan Li, Yi-Ling Qiao, Peter Yichen Chen, Krishna Murthy Jatavallabhula, Ming Lin, Chenfanfu Jiang, and Chuang GanICLR 2023Notable top 25 (top 25 percent of accepted submissions)
PAC-NeRF: Physics Augmented Continuum Neural Radiance Fields for Geometry-Agnostic System IdentificationXuan Li, Yi-Ling Qiao, Peter Yichen Chen, Krishna Murthy Jatavallabhula, Ming Lin, Chenfanfu Jiang, and Chuang GanICLR 2023Notable top 25 (top 25 percent of accepted submissions)Existing approaches to system identification (estimating the physical parameters of an object) from videos assume known object geometries. This precludes their applicability in a vast majority of scenes where object geometries are complex or unknown. In this work, we aim to identify parameters characterizing a physical system from a set of multi-view videos without any assumption on object geometry or topology. To this end, we propose "Physics Augmented Continuum Neural Radiance Fields" (PAC-NeRF), to estimate both the unknown geometry and physical parameters of highly dynamic objects from multi-view videos. We design PAC-NeRF to only ever produce physically plausible states by enforcing the neural radiance field to follow the conservation laws of continuum mechanics. For this, we design a hybrid Eulerian-Lagrangian representation of the neural radiance field, i.e., we use the Eulerian grid representation for NeRF density and color fields, while advecting the neural radiance fields via Lagrangian particles. This hybrid Eulerian-Lagrangian representation seamlessly blends efficient neural rendering with the material point method (MPM) for robust differentiable physics simulation. We validate the effectiveness of our proposed framework on geometry and physical parameter estimation over a vast range of materials, including elastic bodies, plasticine, sand, Newtonian and non-Newtonian fluids, and demonstrate significant performance gain on most tasks.
We integrate a differentiable physics engine with neural radiance fields for simulatneous estimation of geometry and physical properties from multi-view videos
Work primarily done by Xuan when interning with Chuang, who was the lead PI. Chuang came up with the central pitch for this work. I helped design the real-world experiments. My biggest contribution to this project was perhaps that I wrote up bulk of the manuscript.
@inproceedings{pacnerf, title = {PAC-NeRF: Physics Augmented Continuum Neural Radiance Fields for Geometry-Agnostic System Identification}, author = {Li, Xuan and Qiao, Yi-Ling and Chen, {Peter Yichen} and Jatavallabhula, {Krishna Murthy} and Lin, Ming and Jiang, Chenfanfu and Gan, Chuang}, year = {2023}, booktitle = {ICLR}, recognition = {Notable top 25 (top 25 percent of accepted submissions)}, } -
 Learning Correspondence Uncertainty via Differentiable Nonlinear Least SquaresCVPR 2023
Learning Correspondence Uncertainty via Differentiable Nonlinear Least SquaresCVPR 2023We propose a differentiable nonlinear least squares framework to account for uncertainty in relative pose estimation from feature correspondences. Specifically, we introduce a symmetric version of the probabilistic normal epipolar constraint, and an approach to estimate the covariance of feature positions by differentiating through the camera pose estimation procedure. We evaluate our approach on synthetic, as well as the KITTI and EuRoC real-world datasets. On the synthetic dataset, we confirm that our learned covariances accurately approximate the true noise distribution. In real world experiments, we find that our approach consistently outperforms state-of-the-art non-probabilistic and probabilistic approaches, regardless of the feature extraction algorithm of choice.
Work led entirely by Dominik, and Lukas assisted with the formulation of several technical details. Daniel and I offered overarching guidance and support.
@inproceedings{muhle2023cvpr, title = {Learning Correspondence Uncertainty via Differentiable Nonlinear Least Squares}, author = {Muhle, Dominik and Koestler, Lukas and Jatavallabhula, {Krishna Murthy} and Cremers, Daniel}, year = {2023}, booktitle = {CVPR}, }
2022
-

Bayesian Object Models for Robotic Interaction with Differentiable Probabilistic Programming
CoRL 2022A hallmark of human intelligence is the ability to build rich mental models of previously unseen objects from very few interactions. To achieve true, continuous autonomy, robots too must possess this ability. Importantly, to integrate with the probabilistic robotics software stack, such models must encapsulate the uncertainty (resulting from noisy dynamics and observation models) in a prescriptive manner. We present Bayesian Object Models (BOMs): generative (probabilistic) models that encode both the structural and kinodynamic attributes of an object. BOMs are implemented in the form of a differentiable probabilistic program that models latent scene structure, object dynamics, and observation models. This allows for efficient and automated Bayesian inference – samples (object trajectories) drawn from the BOM are compared with a small set of real-world observations and used to compute a likelihood function. Our model comprises a differentiable tree structure sampler and a differentiable physics engine, enabling gradient computation through this likelihood function. This enables gradient-based Bayesian inference to efficiently update the distributional parameters of our model. BOMs outperform several recent approaches, including differentiable physics-based, gradient-free, and neural inference schemes.
We build a differentiable probabilistic physics engine that can estimate posterior distributions over object articulation chains and physical properties
I led this work during my (virtual) internship at NVIDIA in summer 2021
@inproceedings{bom, title = {Bayesian Object Models for Robotic Interaction with Differentiable Probabilistic Programming}, author = {Jatavallabhula, {Krishna Murthy} and Macklin, Miles and Fox, Dieter and Garg, Animesh and Ramos, Fabio}, year = {2022}, booktitle = {CoRL}, featured = {true} } -
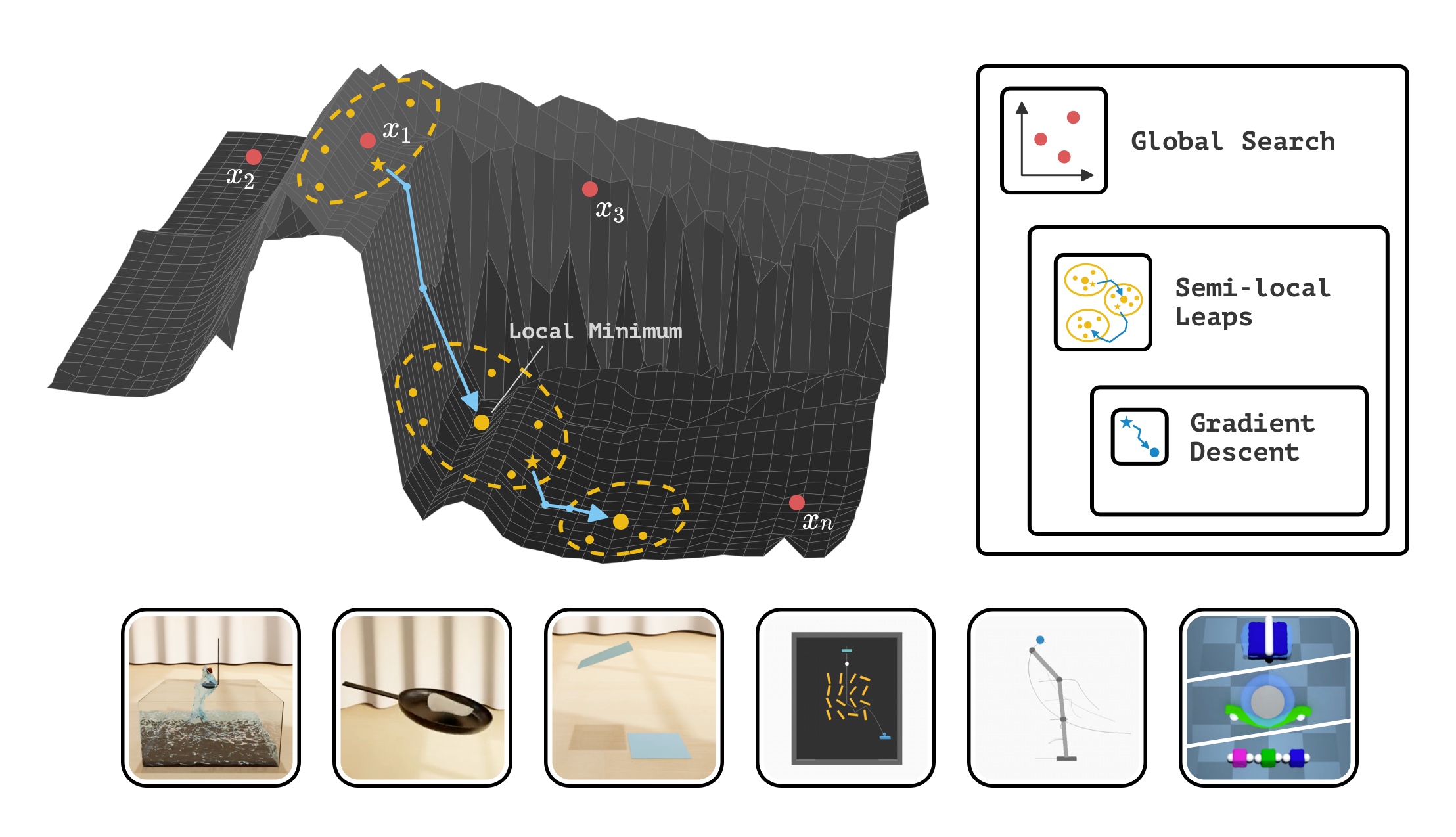 Rethinking Optimization with Differentiable Simulation from a Global PerspectiveCoRL 2022Oral presentation (top 6.5 percent of submissions)
Rethinking Optimization with Differentiable Simulation from a Global PerspectiveCoRL 2022Oral presentation (top 6.5 percent of submissions)Differentiable simulation is a promising toolkit for fast gradient-based policy optimization and system identification. In this work, we study the challenges that differentiable simulation presents when it is not feasible to expect that a single descent reaches a global optimum. We analyze the optimization landscapes of diverse scenarios and find that in dynamic environments with highly deformable objects and fluids, differentiable simulators produce rugged landscapes with useful gradients. We propose a method that combines Bayesian optimization with semi-local leaps to obtain a global search method that can use gradients effectively and maintain robust performance in regions with noisy gradients. We show extensive experiments in simulation, and also validate the method in a real robot setup.
We show that differentiable simulations present difficult optimization landscapes and address this with a method that combines global and local optimization
Rika and Jingyun did nearly all of the work. I was consulted primarily for advice on differentiable simulation. I helped write a few parts of the manuscript.
@inproceedings{bodiffsim, title = {Rethinking Optimization with Differentiable Simulation from a Global Perspective}, author = {Antonova, Rika and Yang, Jingyun and Jatavallabhula, {Krishna Murthy} and Bohg, Jeannette}, year = {2022}, booktitle = {CoRL}, recognition = {Oral presentation (top 6.5 percent of submissions)} } -
 f -Cal: Calibrated aleatoric uncertainty estimation from neural networks for robot perceptionDhaivat Bhatt*, Kaustubh Mani*, Dishank Bansal, Hanju Lee, Krishna Murthy Jatavallabhula, and Liam PaullICRA 2022
f -Cal: Calibrated aleatoric uncertainty estimation from neural networks for robot perceptionDhaivat Bhatt*, Kaustubh Mani*, Dishank Bansal, Hanju Lee, Krishna Murthy Jatavallabhula, and Liam PaullICRA 2022f-Cal is calibration method for probabilistic regression networks. Typical Bayesian neural networks are overconfident in their predictions. For these predictions to be used in downstream tasks, reliable and calibrated uncertainity estimates are critical. f-Cal proposes a simple loss function to remedy this; this can be employed to train any probabilistic neural regressor to produced calibrated estimates of aleatoric uncertainty.
We present a simple approach that uses a variational loss to enforce calibration in probabilistic regression networks
Dhaivat and Kaustubh contributed equally to the experiments. Dishank implemented very early prototypes. Liam came up with this idea. I mentored Dhaivat and Kaustubh closely on this work.
@inproceedings{fcal, title = {f -Cal: Calibrated aleatoric uncertainty estimation from neural networks for robot perception}, author = {Bhatt, Dhaivat and Mani, Kaustubh and Bansal, Dishank and Lee, Hanju and Jatavallabhula, {Krishna Murthy} and Paull, Liam}, year = {2022}, booktitle = {ICRA}, } -
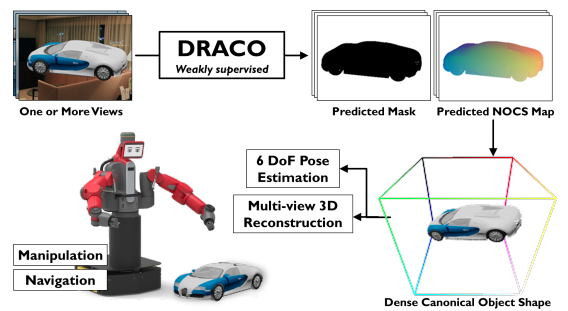 DRACO: Weakly supervised dense reconstruction and canonicalization of objectsRahul Sajnani*, Aadil Mehdi Sanchawala*, Krishna Murthy Jatavallabhula, Srinath Sridhar, and Madhava Krishna KICRA 2022
DRACO: Weakly supervised dense reconstruction and canonicalization of objectsRahul Sajnani*, Aadil Mehdi Sanchawala*, Krishna Murthy Jatavallabhula, Srinath Sridhar, and Madhava Krishna KICRA 2022We present DRACO, a method for Dense Reconstruction And Canonicalization of Object shape from one or more RGB images. Canonical shape reconstruction; estimating 3D object shape in a coordinate space canonicalized for scale, rotation, and translation parameters—is an emerging paradigm that holds promise for a multitude of robotic applications. Prior approaches either rely on painstakingly gathered dense 3D supervision, or produce only sparse canonical representations, limiting real-world applicability. DRACO performs dense canonicalization using only weak supervision in the form of camera poses and semantic keypoints at train time. During inference, DRACO predicts dense object-centric depth maps in a canonical coordinate-space, solely using one or more RGB images of an object. Extensive experiments on canonical shape reconstruction and pose estimation show that DRACO is competitive or superior to fully-supervised methods.
We present a weakly supervised approach that reconstructs objects in a canonical coordinate space
I mentored Rahul and Aadil on this project. Srinath and Madhav were the lead PIs, and likely contributed more than me.
@inproceedings{draco, title = {DRACO: Weakly supervised dense reconstruction and canonicalization of objects}, author = {Sajnani, Rahul and Sanchawala, {Aadil Mehdi} and Jatavallabhula, {Krishna Murthy} and Sridhar, Srinath and K, {Madhava Krishna}}, year = {2022}, booktitle = {ICRA}, }
2021
-
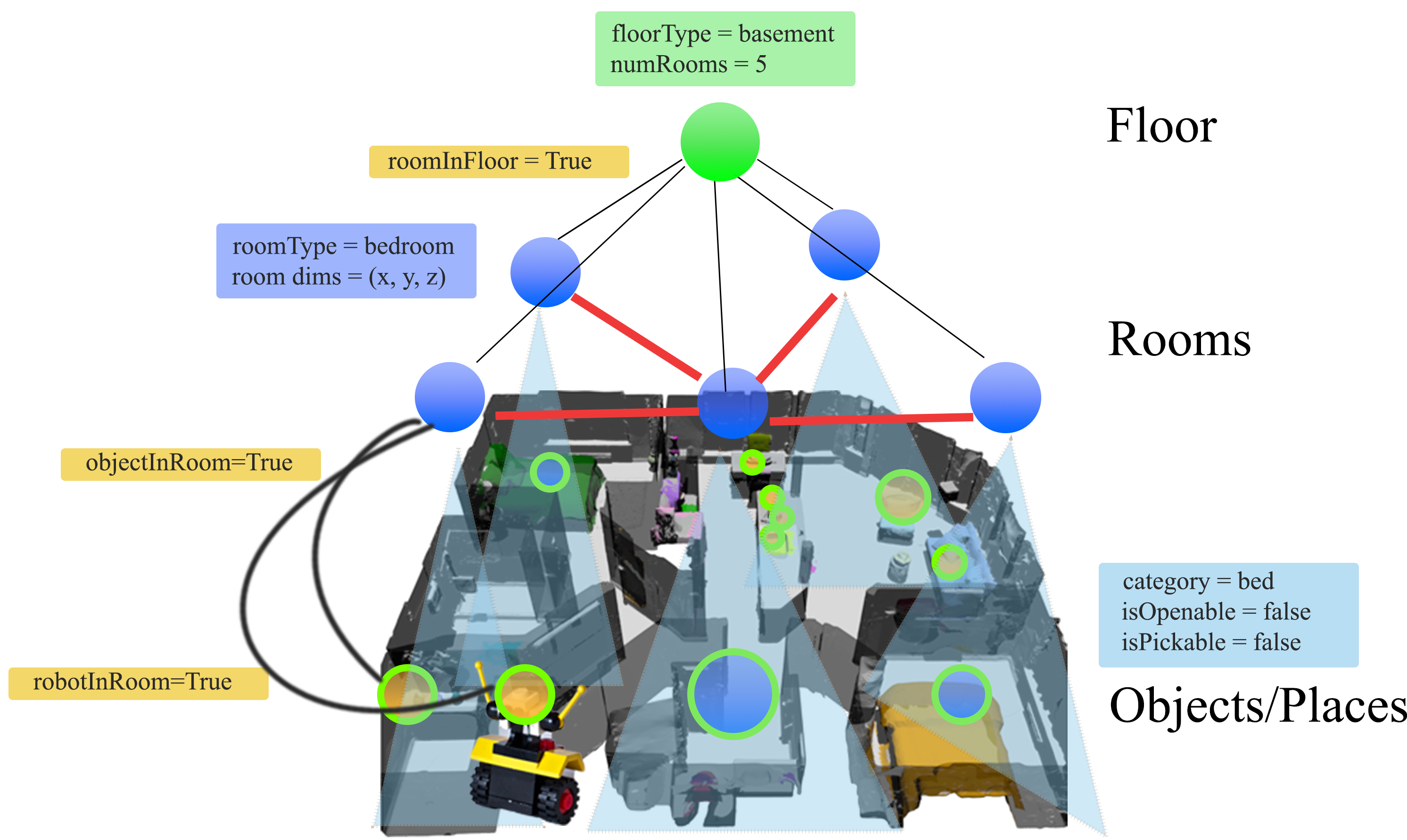
Taskography: Evaluating robot task planning over large 3D scene graphs
Chris Agia*, Krishna Murthy Jatavallabhula*, Mohamed Khodeir, Ondrej Miksik, Vibhav Vineet, Mustafa Mukadam, Liam Paull, and Florian ShkurtiCoRL 20213D scene graphs (3DSGs) are an emerging description; unifying symbolic, topological, and metric scene representations. However, typical 3DSGs contain hundreds of objects and symbols even for small environments; rendering task planning on the \emphfull graph impractical. We construct \textbfTaskography, the first large-scale robotic task planning benchmark over 3DSGs. While most benchmarking efforts in this area focus on \emphvision-based planning, we systematically study \emphsymbolic planning, to decouple planning performance from visual representation learning. We observe that, among existing methods, neither classical nor learning-based planners are capable of real-time planning over \emphfull 3DSGs. Enabling real-time planning demands progress on \emphboth (a) sparsifying 3DSGs for tractable planning and (b) designing planners that better exploit 3DSG hierarchies. Towards the former goal, we propose \textbfScrub, a task-conditioned 3DSG sparsification method; enabling classical planners to match (and surpass) state-of-the-art learning-based planners. Towards the latter goal, we propose \textbfSeek, a procedure enabling learning-based planners to exploit 3DSG structure, reducing the number of replanning queries required by current best approaches by an order of magnitude. We will open-source all code and baselines to spur further research along the intersections of robot task planning, learning and 3DSGs.
We present a large-scale benchmark and performant approaches for long-horizon task planning over large 3D scene graphs
Idea was conceived, led, and implemented by Chris and I. Chris focused more on the benchmark. I focused on the SCRUB and SEEK algorithms. Mohamed helped implement several optimal planners. Chris implemented the Taskography-API.
@inproceedings{taskography, title = {Taskography: Evaluating robot task planning over large 3D scene graphs}, author = {Agia, Chris and Jatavallabhula, {Krishna Murthy} and Khodeir, Mohamed and Miksik, Ondrej and Vineet, Vibhav and Mukadam, Mustafa and Paull, Liam and Shkurti, Florian}, year = {2021}, booktitle = {CoRL}, featured = {true} } -

gradSim: Differentiable simulation for system identification and visuomotor control
Krishna Murthy Jatavallabhula*, Miles Macklin*, Florian Golemo, Vikram Voleti, Linda Petrini, Martin Weiss, Breandan Considine, Jerome Parent-Levesque, Kevin Xie, Kenny Erleben, Liam Paull, Florian Shkurti, Derek Nowrouzezahrai, and Sanja FidlerICLR 2021In this paper, we tackle the problem of estimating object physical properties such as mass, friction, and elasticity directly from video sequences. Such a system identification problem is fundamentally ill-posed due to the loss of information during image formation. Current best solutions to the problem require precise 3D labels which are labor intensive to gather, and infeasible to create for many systems such as deformable solids or cloth. In this work we present gradSim, a framework that overcomes the dependence on 3D supervision by combining differentiable multiphysics simulation and differentiable rendering to jointly model the evolution of scene dynamics and image formation. This unique combination enables backpropagation from pixels in a video sequence through to the underlying physical attributes that generated them. Furthermore, our unified computation graph across dynamics and rendering engines enables the learning of challenging visuomotor control tasks, without relying on state-based (3D) supervision, while obtaining performance competitive to/better than techniques that require precise 3D labels.
Differentiable models of time-varying dynamics and image formation pipelines result in highly accurate physical parameter estimation from video and visuomotor control.
This idea was jointly conceived in a meeting which included me, Derek, Breandan, Martin, Bhairav Mehta, and Maxime Chevalier-Boisvert. Martin prototyped an initial differentiable billiards engine. I implemented the first rigid-body engine, integrated it with a differentiable renderer, and setup sys-id experiments. Miles and I then joined forces, with him focusing on the physics engine and me focusing on the physics + rendering combination and overall systems integration. I ran all of the experiments for this paper. Florian (Golemo) and Vikram created the datasets, designed experiments, and also helped with code and the manuscript. All authors participated in writing the manuscript and the author response phase. Florian (Shkurti), Derek, and Sanja nearly equally co-advised on this effort.
@inproceedings{gradsim, title = {gradSim: Differentiable simulation for system identification and visuomotor control}, author = {Jatavallabhula, {Krishna Murthy} and Macklin, Miles and Golemo, Florian and Voleti, Vikram and Petrini, Linda and Weiss, Martin and Considine, Breandan and Parent-Levesque, Jerome and Xie, Kevin and Erleben, Kenny and Paull, Liam and Shkurti, Florian and Nowrouzezahrai, Derek and Fidler, Sanja}, year = {2021}, booktitle = {ICLR}, featured = {true} }
2020
-
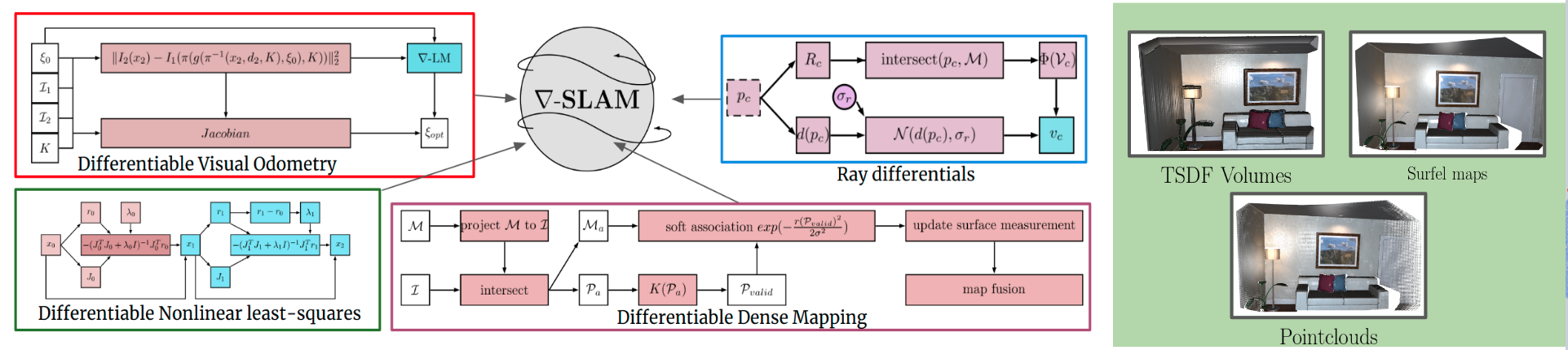
gradSLAM: Dense SLAM meets automatic differentiation
Krishna Murthy Jatavallabhula, Ganesh Iyer, and Liam PaullICRA 2020The question of “representation” is central in the context of dense simultaneous localization and mapping (SLAM). Newer learning-based approaches have the potential to leverage data or task performance to directly inform the choice of representation. However, learning representations for SLAM has been an open question, because traditional SLAM systems are not end-to-end differentiable. In this work, we present gradSLAM, a differentiable computational graph take on SLAM. Leveraging the automatic differentiation capabilities of computational graphs, gradSLAM enables the design of SLAM systems that allow for gradient-based learning across each of their components, or the system as a whole. This is achieved by creating differentiable alternatives for each non-differentiable component in a typical dense SLAM system. Specifically, we demonstrate how to design differentiable trust-region optimizers, surface measurement and fusion schemes, as well as differentiate over rays, without sacrificing performance. This amalgamation of dense SLAM with computational graphs enables us to backprop all the way from 3D maps to 2D pixels, opening up new possibilities in gradient-based learning for SLAM.
We present end-to-end differentiable dense SLAM systems that open up new possibilites for integrating deep learning and SLAM
I came up with the idea and led this work. Ganesh Iyer was instrumental with implementing the surfel and point-based fusion pipelines.
@inproceedings{gradslam, title = {gradSLAM: Dense SLAM meets automatic differentiation}, author = {Jatavallabhula, {Krishna Murthy} and Iyer, Ganesh and Paull, Liam}, year = {2020}, booktitle = {ICRA}, featured = {true} } -
 AutoLay: Benchmarking Monocular Layout EstimationIROS 2020
AutoLay: Benchmarking Monocular Layout EstimationIROS 2020Amodal layout estimation is the task of estimating a semantic occupancy map in bird’s-eye view, given a monocular image or video. The term amodal implies that we estimate occupancy and semantic labels even for parts of the world that are occluded in image space. In this work, we introduce AutoLay, a new dataset and benchmark for this task. AutoLay provides annotations in 3D, in bird’s-eye view, and in image space. We provide high quality labels for sidewalks, vehicles, crosswalks, and lanes. We evaluate several approaches on sequences from the KITTI and Argoverse datasets.
We present a dataset and introduce a new benchmark for *amodal* layout estimation from monocular imagery
Kaustubh led this work. I came up with the idea, mentored Kaustubh (admittedly, relatively sparsely), and helped write some of the manuscript. Sai, and particularly Kaustubh, were instrumental in driving this work to completion.
@inproceedings{autolay, title = {AutoLay: Benchmarking Monocular Layout Estimation}, author = {Mani, Kaustubh and Shankar, Sai and Jatavallabhula, {Krishna Murthy} and K, {Madhava Krishna}}, year = {2020}, booktitle = {IROS}, } -
 MonoLayout: Amodal scene layout from a single imageKaustubh Mani, Swapnil Daga, Shubhika Garg, Sai Shankar, Krishna Murthy Jatavallabhula, and Madhava Krishna KWACV 2020
MonoLayout: Amodal scene layout from a single imageKaustubh Mani, Swapnil Daga, Shubhika Garg, Sai Shankar, Krishna Murthy Jatavallabhula, and Madhava Krishna KWACV 2020In this paper, we address the novel, highly challenging problem of estimating the layout of a complex urban driving scenario. Given a single color image captured from a driving platform, we aim to predict the bird’s-eye view layout of the road and other traffic participants. The estimated layout should reason beyond what is visible in the image, and compensate for the loss of 3D information due to projection. We dub this problem "amodal scene layout estimation", which involves hallucinating scene layout for even parts of the world that are occluded in the image. To this end, we present MonoLayout, a deep neural network for real-time amodal scene layout estimation from a single image. MonoLayout maps a color image of a scene into a multi-channel occupancy grid in bird’s-eye view, where each channel represents occupancy probabilities of various scene components. We represent scene layout as a multi-channel semantic occupancy grid, and leverage adversarial feature learning to hallucinate plausible completions for occluded image parts. We extend several state-of-the-art approaches for road-layout estimation and vehicle occupancy estimation in bird’s-eye view to the amodal setup and thoroughly evaluate against them. By leveraging temporal sensor fusion to generate training labels, we significantly outperform current art over a number of datasets.
We present a neural network that "hallucinates" the layout of a road scene from a single image, including scene parts that are outside the bounds of the image
Kaustubh led this work. I came up with the idea, served as mentor, and helped write bulk of the manuscript.
@inproceedings{monolayout, title = {MonoLayout: Amodal scene layout from a single image}, author = {Mani, Kaustubh and Daga, Swapnil and Garg, Shubhika and Shankar, Sai and Jatavallabhula, {Krishna Murthy} and K, {Madhava Krishna}}, year = {2020}, booktitle = {WACV}, } -
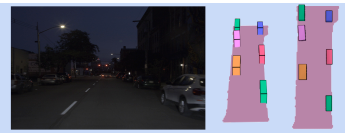
 Multi-object monocular SLAM for dynamic environmentsGokul Nair, Swapnil Daga, Rahul Sajnani, Anirudha Ramesh, Junaid Ahmed Ansari, Krishna Murthy Jatavallabhula, and Madhava Krishna KIntelligent Vehicles Symposium (IV) 2020Finalist - Best Student Paper Award
Multi-object monocular SLAM for dynamic environmentsGokul Nair, Swapnil Daga, Rahul Sajnani, Anirudha Ramesh, Junaid Ahmed Ansari, Krishna Murthy Jatavallabhula, and Madhava Krishna KIntelligent Vehicles Symposium (IV) 2020Finalist - Best Student Paper AwardIn this paper, we tackle the problem of multibody SLAM from a monocular camera. The term multibody, implies that we track the motion of the camera, as well as that of other dynamic participants in the scene. The quintessential challenge in dynamic scenes is unobservability; it is not possible to unambiguously triangulate a moving object from a moving monocular camera. Existing approaches solve restricted variants of the problem, but the solutions suffer relative scale ambiguity (i.e., a family of infinitely many solutions exist for each pair of motions in the scene). We solve this rather intractable problem by leveraging single-view metrology, advances in deep learning, and category-level shape estimation. We propose a multi posegraph optimization formulation, to resolve the relative and absolute scale factor ambiguities involved. This optimization helps us reduce the average error in trajectories of multiple bodies over real-world datasets, such as KITTI. To the best of our knowledge, our method is the first practical monocular multi-body SLAM system to perform dynamic multi-object and ego localization in a unified framework in metric scale.
We present a monocular object SLAM system that tracks not just the camera, but also other moving objects in the scene
I mentored Gokul and Swapnil on this project. I also wrote a part of the manuscript.
@inproceedings{nair2020iv, title = {Multi-object monocular SLAM for dynamic environments}, author = {Nair, Gokul and Daga, Swapnil and Sajnani, Rahul and Ramesh, Anirudha and Ansari, {Junaid Ahmed} and Jatavallabhula, {Krishna Murthy} and K, {Madhava Krishna}}, year = {2020}, booktitle = {Intelligent Vehicles Symposium (IV)}, recognition = {Finalist - Best Student Paper Award} }
2019
-
 MapLite: Autonomous intersection navigation without detailed prior mapsTeddy Ort, Krishna Murthy Jatavallabhula, Rohan Banerjee, Sai Krishna Gottipati, Dhaivat Bhatt, Igor Gilitschenski, Liam Paull, and Daniela RusRobotics and Automation Letters 2019Best paper award
MapLite: Autonomous intersection navigation without detailed prior mapsTeddy Ort, Krishna Murthy Jatavallabhula, Rohan Banerjee, Sai Krishna Gottipati, Dhaivat Bhatt, Igor Gilitschenski, Liam Paull, and Daniela RusRobotics and Automation Letters 2019Best paper awardIn this work, we present MapLite- a one-click autonomous navigation system capable of piloting a vehicle to an arbitrary desired destination point given only a sparse publicly available topometric map (from OpenStreetMap). The onboard sensors are used to segment the road region and register the topometric map in order to fuse the high-level navigation goals with a variational path planner in the vehicle frame. This enables the system to plan trajectories that correctly navigate road intersections without the use of an external localization system such as GPS or a detailed prior map. Since the topometric maps already exist for the vast majority of roads, this solution greatly increases the geographical scope for autonomous mobility solutions. We implement MapLite on a full-scale autonomous vehicle and exhaustively test it on over 15 km of road including over 100 autonomous intersection traversals. We further extend these results through simulated testing to validate the system on complex road junction topologies such as traffic circles.
MapLite is a one-click autonomous navigation system for a vehicle that only uses OpenStreetMap data and local sensing
Teddy did nearly all of this work. I helped design the topometric registration algorithm and write the manuscript.
@inproceedings{maplite, title = {MapLite: Autonomous intersection navigation without detailed prior maps}, author = {Ort, Teddy and Jatavallabhula, {Krishna Murthy} and Banerjee, Rohan and Gottipati, {Sai Krishna} and Bhatt, Dhaivat and Gilitschenski, Igor and Paull, Liam and Rus, Daniela}, year = {2019}, booktitle = {Robotics and Automation Letters}, recognition = {Best paper award} } -
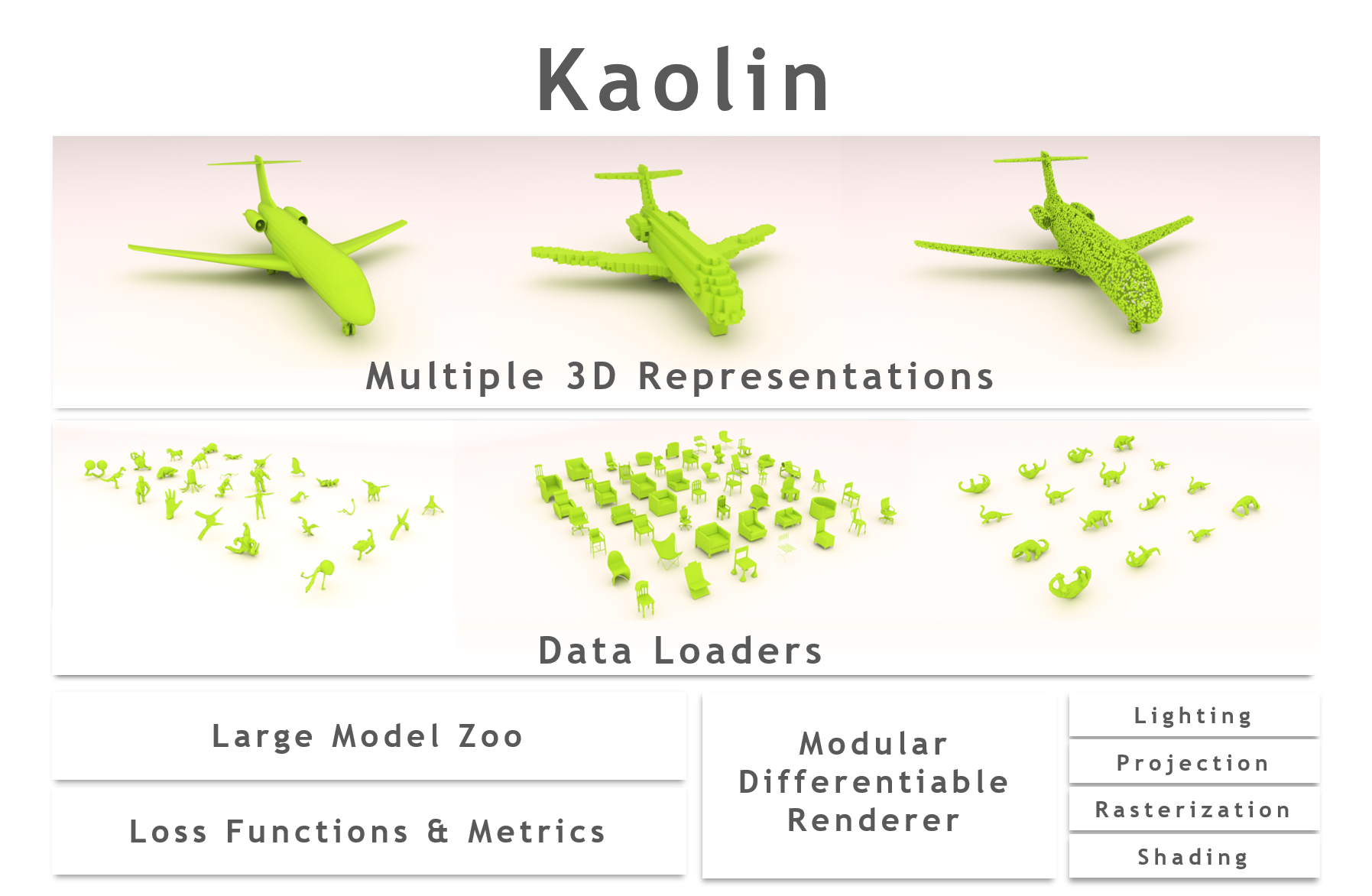
Kaolin: A PyTorch Library for Accelerating 3D Deep Learning Research
Krishna Murthy Jatavallabhula*, Edward Smith*, Jean-Francois Lafleche, Clement Fuji Tsang, Artem Rozantsev, Wenzheng Chen, Tommy Xiang, Rev Lebaredian, and Sanja FidlerWhitepaper 2019Kaolin is a PyTorch library aiming to accelerate 3D deep learning research. Kaolin provides efficient implementations of differentiable 3D modules for use in deep learning systems. With functionality to load and preprocess several popular 3D datasets, and native functions to manipulate meshes, pointclouds, signed distance functions, and voxel grids, Kaolin mitigates the need to write wasteful boilerplate code. Kaolin packages together several differentiable graphics modules including rendering, lighting, shading, and view warping. Kaolin also supports an array of loss functions and evaluation metrics for seamless evaluation and provides visualization functionality to render the 3D results. Importantly, we curate a comprehensive model zoo comprising many state-of-the-art 3D deep learning architectures, to serve as a starting point for future research endeavours.
Kaolin is a PyTorch library aimed at accelerating 3D deep learning research.
Edward and I led this work during our 2019 internships at NVIDIA. It has since been maintained and developed by several others, notably, Clement, Masha Shugrina, and Towaki Takikawa
@inproceedings{kaolin, title = {Kaolin: A PyTorch Library for Accelerating 3D Deep Learning Research}, author = {Jatavallabhula, {Krishna Murthy} and Smith, Edward and Lafleche, Jean-Francois and {Fuji Tsang}, Clement and Rozantsev, Artem and Chen, Wenzheng and Xiang, Tommy and Lebaredian, Rev and Fidler, Sanja}, year = {2019}, booktitle = {Whitepaper}, featured = {true} } -
 Deep Active LocalizationSai Krishna Gottipati*, Keehong Seo*, Krishna Murthy Jatavallabhula, Dhaivat Bhatt, Vincent Mai, and Liam PaullRobotics and Automation Letters 2019
Deep Active LocalizationSai Krishna Gottipati*, Keehong Seo*, Krishna Murthy Jatavallabhula, Dhaivat Bhatt, Vincent Mai, and Liam PaullRobotics and Automation Letters 2019Active localization is the problem of generating robot actions that allow it to maximally disambiguate its pose within a reference map. Traditional approaches to this use an information-theoretic criterion for action selection and hand-crafted perceptual models. In this work we propose an end-to-end differentiable method for learning to take informative actions that is trainable entirely in simulation and then transferable to real robot hardware with zero refinement. The system is composed of two modules - a convolutional neural network for perception, and a deep reinforcement learned planning module. We introduce a multi-scale approach to the learned perceptual model since the accuracy needed to perform action selection with reinforcement learning is much less than the accuracy needed for robot control. We demonstrate that the resulting system outperforms using the traditional approach for either perception or planning. We also demonstrate our approaches robustness to different map configurations and other nuisance parameters through the use of domain randomization in training. The code is also compatible with the OpenAI gym framework, as well as the Gazebo simulator.
We demonstrate the applicability of a learned perception model and an exploration policy applied to active localization on real robots
Sai and Keehong did most of this work. I was only loosely involved in a mentorship role
@inproceedings{dal, title = {Deep Active Localization}, author = {Gottipati, {Sai Krishna} and Seo, Keehong and Jatavallabhula, {Krishna Murthy} and Bhatt, Dhaivat and Mai, Vincent and Paull, Liam}, year = {2019}, booktitle = {Robotics and Automation Letters}, } -
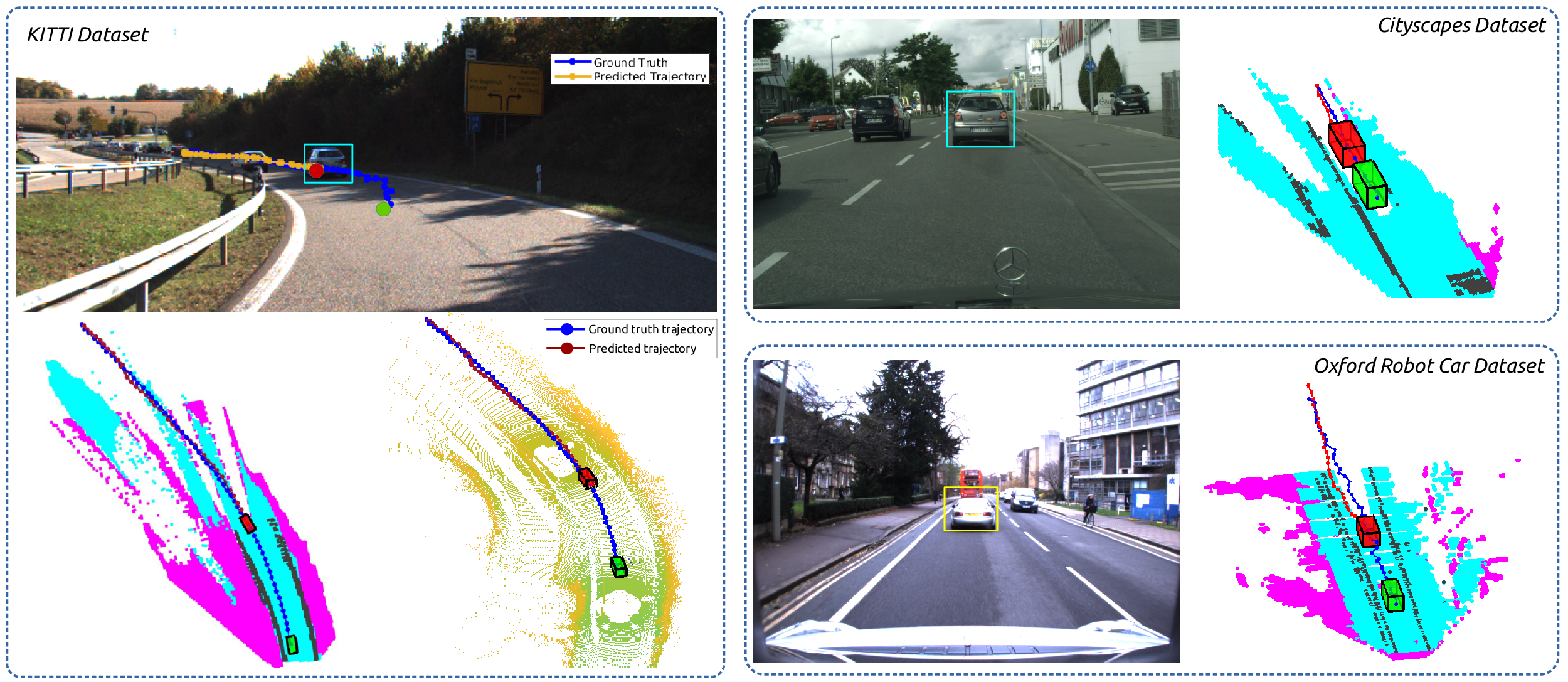 INFER: INtermediate representations for FuturE pRedictionShashank Srikanth, Junaid Ahmed Ansari, Karnik Ram, Sarthak Sharma, Krishna Murthy Jatavallabhula, and Madhava Krishna KIROS 2019
INFER: INtermediate representations for FuturE pRedictionShashank Srikanth, Junaid Ahmed Ansari, Karnik Ram, Sarthak Sharma, Krishna Murthy Jatavallabhula, and Madhava Krishna KIROS 2019Deep learning methods have ushered in a new era for computer vision and robotics. With very accurate methods for object detection and semantic segmentation, we are now at a juncture where we can envisage the application of these techniques to perform higher-order understanding. One such application which we consider in this work, is predicting future states of traffic participants in urban driving scenarios. Specifically, we argue that constructing intermediate representations of the world using off-the-shelf computer vision models for semantic segmentation and object detection, we can train models that account for the multi-modality of future states, and at the same time transfer well across different train and test distributions (datasets). Our approach, dubbed INFER (INtermediate representations for distant FuturE pRediction), involves training an autoregressive model that takes in an intermediate representation of past states of the world, and predicts a multimodal distribution over plausible future states. The model consists of an Encoder-Decoder with ConvLSTM present along the skip connections, and in between the Encoder-Decoder. The network takes an intermediate representation of the scene and predicts the future locations of the Vehicle of Interest (VoI). We outperform the current best future prediction model on KITTI while predicting deep into the future (3 sec, 4 sec) by a significant margin. Contrary to most approaches dealing with future prediction that do not generalize well to datasets that they have not been trained on, we test our method on different datasets like Oxford RobotCar and Cityscapes, and show that the network performs well across these datasets which differ in scene layout, weather conditions, and also generalizes well across cross-sensor modalities. We carry out a thorough ablation study on our intermediate representation that captures the role played by different semantics. We conclude the results section by showcasing an important use case of future prediction- multi object tracking and exhibit results on select sequences from KITTI and Cityscapes.
INFER demonstrates the applicability of intermediate representations for zero-shot transferrable trajectory forecasting of vehicles in urban driving scenarios
Shashank led this work. I came up with the idea, mentored the work, and wrote bulk of the manuscript.
@inproceedings{infer, title = {INFER: INtermediate representations for FuturE pRediction}, author = {Srikanth, Shashank and Ansari, {Junaid Ahmed} and Ram, Karnik and Sharma, Sarthak and Jatavallabhula, {Krishna Murthy} and K, {Madhava Krishna}}, year = {2019}, booktitle = {IROS}, }
2018
-
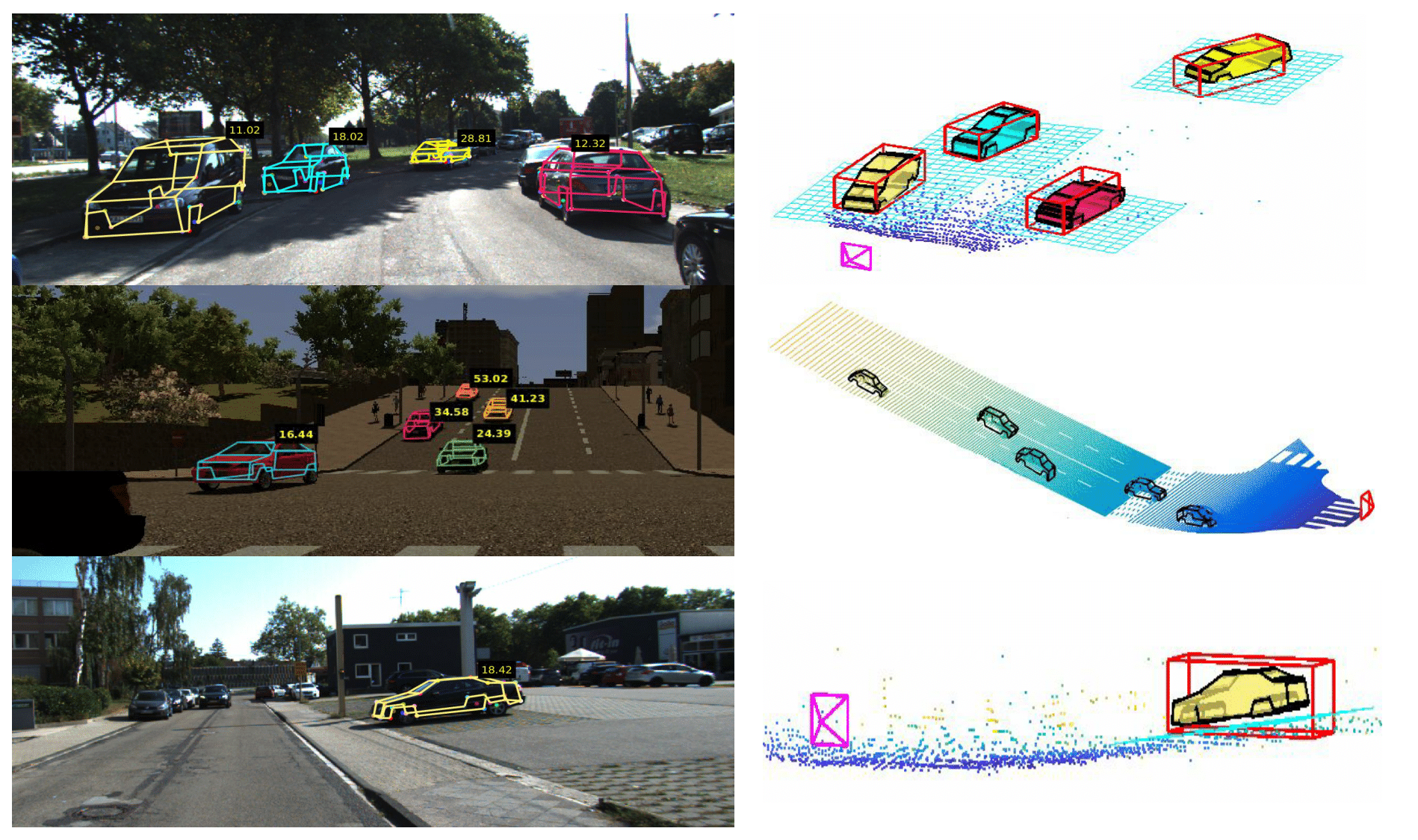 The Earth ain’t Flat: Monocular Reconstruction of Vehicles on Steep and Graded Roads from a Moving CameraJunaid Ahmed Ansari*, Sarthak Sharma*, Anshuman Majumdar, Krishna Murthy Jatavallabhula, and Madhava Krishna KIROS 2018
The Earth ain’t Flat: Monocular Reconstruction of Vehicles on Steep and Graded Roads from a Moving CameraJunaid Ahmed Ansari*, Sarthak Sharma*, Anshuman Majumdar, Krishna Murthy Jatavallabhula, and Madhava Krishna KIROS 2018Accurate localization of other traffic participants is a vital task in autonomous driving systems. State-of-the-art systems employ a combination of sensing modalities such as RGB cameras and LiDARs for localizing traffic participants, but most such demonstrations have been confined to plain roads. We demonstrate, to the best of our knowledge, the first results for monocular object localization and shape estimation on surfaces that do not share the same plane with the moving monocular camera. We approximate road surfaces by local planar patches and use semantic cues from vehicles in the scene to initialize a local bundle-adjustment like procedure that simultaneously estimates the pose and shape of the vehicles, and the orientation of the local ground plane on which the vehicle stands as well. We evaluate the proposed approach on the KITTI and SYNTHIA-SF benchmarks, for a variety of road plane configurations. The proposed approach significantly improves the state-of-the-art for monocular object localization on arbitrarily-shaped roads.
We demonstrate monocular object localization and wireframe (shape) estimation on extremely steep and graded roads
Junaid and Sarthak led this work. I mentored them closely on this project and helped write the manuscript.
@inproceedings{ansari2018steep, title = {The Earth ain’t Flat: Monocular Reconstruction of Vehicles on Steep and Graded Roads from a Moving Camera}, author = {Ansari, {Junaid Ahmed} and Sharma, Sarthak and Majumdar, Anshuman and Jatavallabhula, {Krishna Murthy} and K, {Madhava Krishna}}, year = {2018}, booktitle = {IROS}, } -
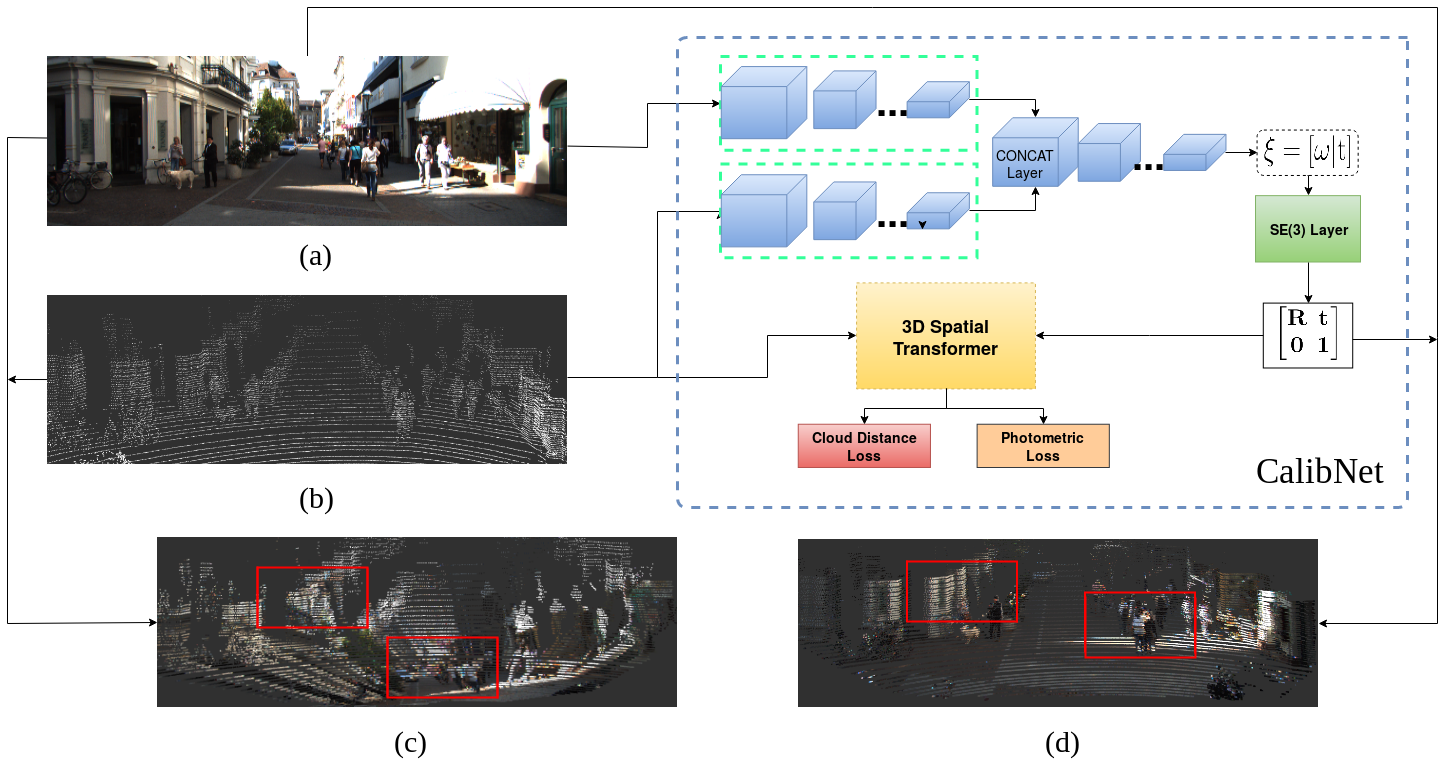 CalibNet: Self-Supervised Extrinsic Calibration using 3D Spatial Transformer NetworksIROS 2018
CalibNet: Self-Supervised Extrinsic Calibration using 3D Spatial Transformer NetworksIROS 20183D LiDARs and 2D cameras are increasingly being used alongside each other in sensor rigs for perception tasks. Before these sensors can be used to gather meaningful data, however, their extrinsics (and intrinsics) need to be accurately calibrated, as the performance of the sensor rig is extremely sensitive to these calibration parameters. A vast majority of existing calibration techniques require significant amounts of data and/or calibration targets and human effort, severely impacting their applicability in large-scale production systems. We address this gap with CalibNet - a self-supervised deep network capable of automatically estimating the 6-DoF rigid body transformation between a 3D LiDAR and a 2D camera in real-time. CalibNet alleviates the need for calibration targets, thereby resulting in significant savings in calibration efforts. During training, the network only takes as input a LiDAR point cloud, the corresponding monocular image, and the camera calibration matrix K. At train time, we do not impose direct supervision (i.e., we do not directly regress to the calibration parameters, for example). Instead, we train the network to predict calibration parameters that maximize the geometric and photometric consistency of the input images and point clouds. CalibNet learns to iteratively solve the underlying geometric problem and accurately predicts extrinsic calibration parameters for a wide range of mis-calibrations, without requiring retraining or domain adaptation.
CalibNet is a geometrically-supervised deep neural network for the extrinsic calibration of lidar-stereo camera rigs
Ganesh led this work. I had the initial idea, and Ganesh had clever tweaks that got it to work in practice.
@inproceedings{calibnet, title = {CalibNet: Self-Supervised Extrinsic Calibration using 3D Spatial Transformer Networks}, author = {Iyer, Ganesh and Ram, Karnik and Jatavallabhula, {Krishna Murthy} and K, {Madhava Krishna}}, year = {2018}, booktitle = {IROS}, } -
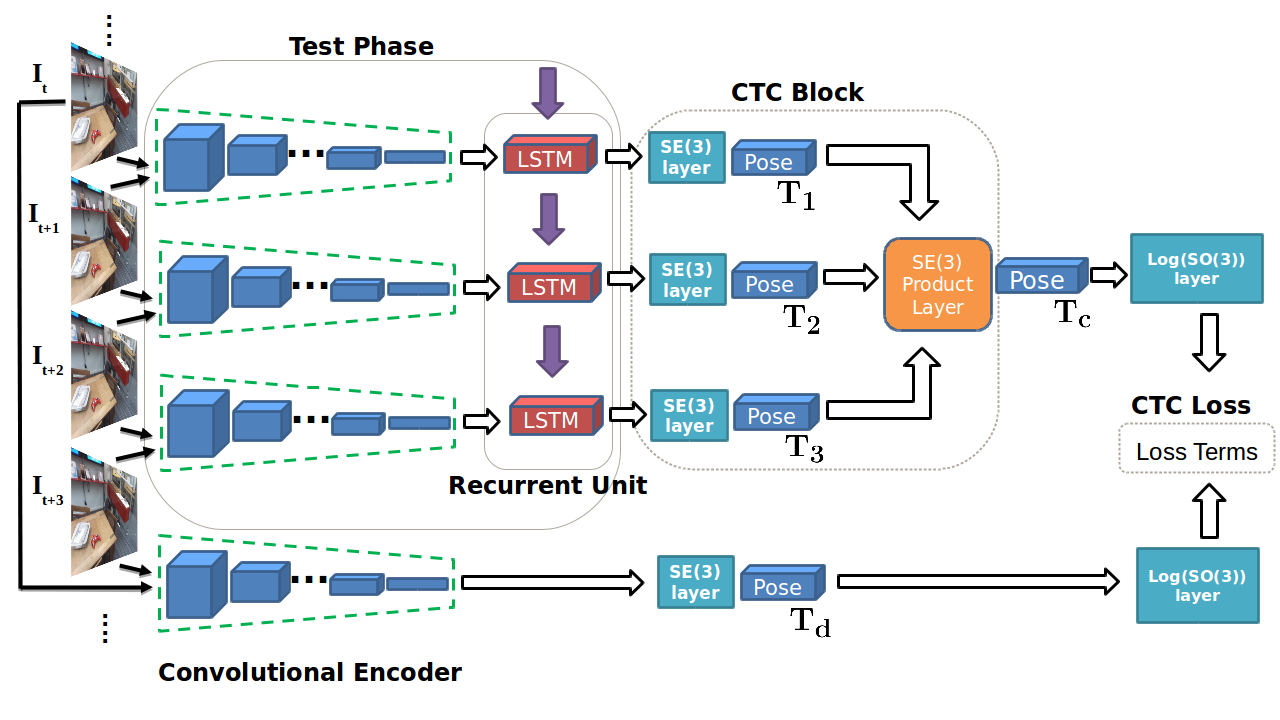 Geometric Consistency for Self-Supervised End-to-End Visual OdometryCVPR Workshops 2018
Geometric Consistency for Self-Supervised End-to-End Visual OdometryCVPR Workshops 2018With the success of deep learning based approaches in tackling challenging problems in computer vision, a wide range of deep architectures have recently been proposed for the task of visual odometry (VO) estimation. Most of these proposed solutions rely on supervision, which requires the acquisition of precise ground-truth camera pose information, collected using expensive motion capture systems or high-precision IMU/GPS sensor rigs. In this work, we propose an unsupervised paradigm for deep visual odometry learning. We show that using a noisy teacher, which could be a standard VO pipeline, and by designing a loss term that enforces geometric consistency of the trajectory, we can train accurate deep models for VO that do not require ground-truth labels. We leverage geometry as a self-supervisory signal and propose "Composite Transformation Constraints (CTCs)", that automatically generate supervisory signals for training and enforce geometric consistency in the VO estimate. We also present a method of characterizing the uncertainty in VO estimates thus obtained. To evaluate our VO pipeline, we present exhaustive ablation studies that demonstrate the efficacy of end-to-end, self-supervised methodologies to train deep models for monocular VO. We show that leveraging concepts from geometry and incorporating them into the training of a recurrent neural network results in performance competitive to supervised deep VO methods.
We use the compositional property of transformations to self-supervise learning of visual odometry from images
Ganesh contributed to this work more than me. I came up with the idea, but he got this to work.
@inproceedings{ctcnet, title = {Geometric Consistency for Self-Supervised End-to-End Visual Odometry}, author = {Iyer, Ganesh and Jatavallabhula, {Krishna Murthy} and Gupta, Gunshi and K, {Madhava Krishna} and Paull, Liam}, year = {2018}, booktitle = {CVPR Workshops}, } -
 Beyond Pixels: Leveraging Geometry and Shape Cues for Multi-Object TrackingSarthak Sharma*, Junaid Ahmed Ansari*, Krishna Murthy Jatavallabhula, and Madhava Krishna KICRA 2018
Beyond Pixels: Leveraging Geometry and Shape Cues for Multi-Object TrackingSarthak Sharma*, Junaid Ahmed Ansari*, Krishna Murthy Jatavallabhula, and Madhava Krishna KICRA 2018This paper introduces geometry and object shape and pose costs for multi-object tracking in urban driving scenarios. Using images from a monocular camera alone, we devise pairwise costs for object tracks, based on several 3D cues such as object pose, shape, and motion. The proposed costs are agnostic to the data association method and can be incorporated into any optimization framework to output the pairwise data associations. These costs are easy to implement, can be computed in real-time, and complement each other to account for possible errors in a tracking-by-detection framework. We perform an extensive analysis of the designed costs and empirically demonstrate consistent improvement over the state-of-the-art under varying conditions that employ a range of object detectors, exhibit a variety in camera and object motions, and, more importantly, are not reliant on the choice of the association framework. We also show that, by using the simplest of associations frameworks (two-frame Hungarian assignment), we surpass the state-of-the-art in multi-object-tracking on road scenes.
We present a monocular multi-object tracker that uses simple 3D cues and obtained (in 2018) state-of-the-art results.
I came up with this idea and mentored Sarthak and Junaid on this work. I also wrote most of the manuscript.
@inproceedings{beyondpixels, title = {Beyond Pixels: Leveraging Geometry and Shape Cues for Multi-Object Tracking}, author = {Sharma, Sarthak and Ansari, {Junaid Ahmed} and Jatavallabhula, {Krishna Murthy} and and K, {Madhava Krishna}}, year = {2018}, booktitle = {ICRA}, } -
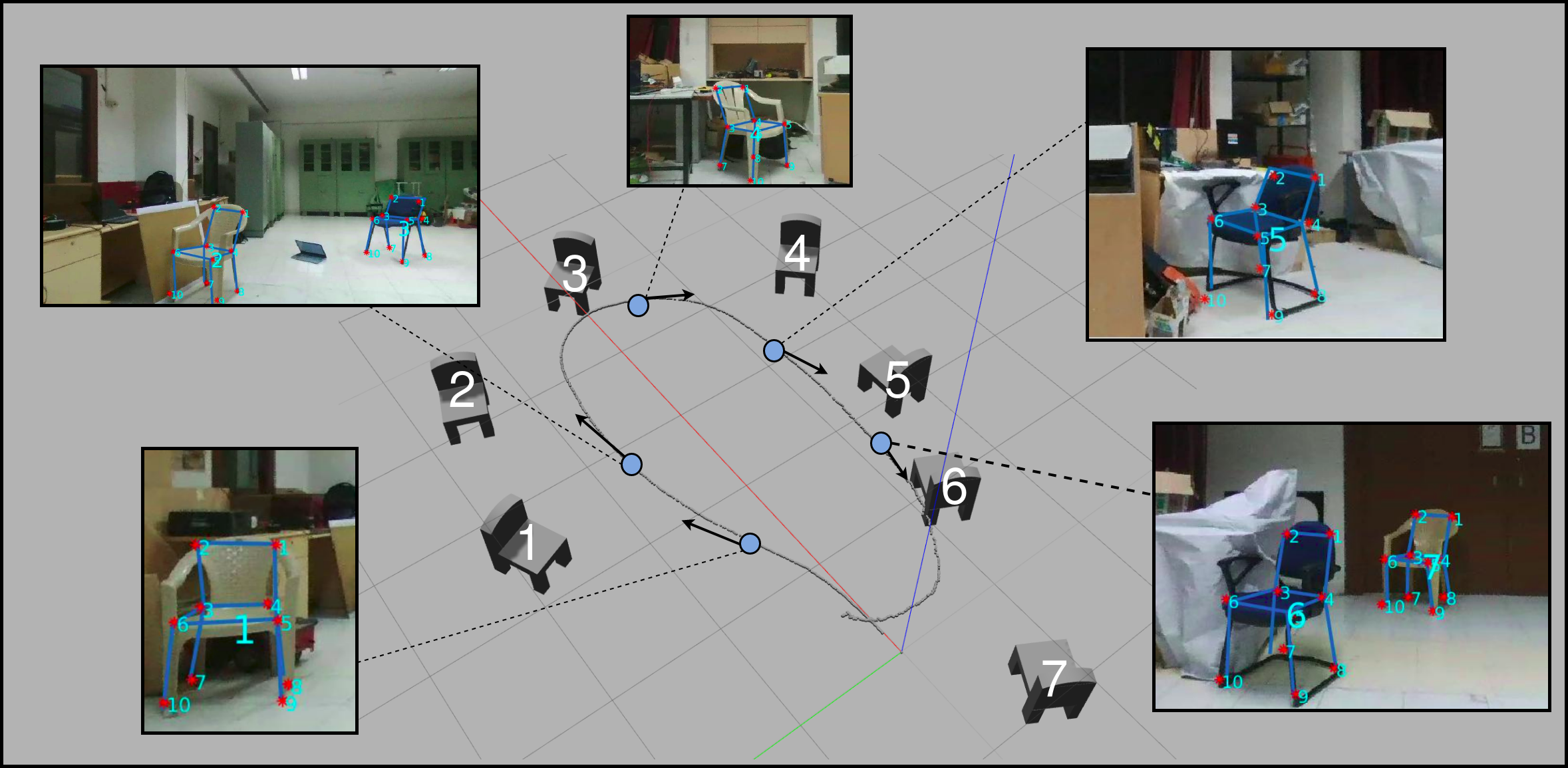 Constructing Category-Specific Models for Monocular Object SLAMParv Parkhiya, Rishabh Khawad, Krishna Murthy Jatavallabhula, Madhava Krishna K, and Brojeshwar BhowmickICRA 2018
Constructing Category-Specific Models for Monocular Object SLAMParv Parkhiya, Rishabh Khawad, Krishna Murthy Jatavallabhula, Madhava Krishna K, and Brojeshwar BhowmickICRA 2018We present a new paradigm for real-time object-oriented SLAM with a monocular camera. Contrary to previous approaches, that rely on object-level models, we construct category-level models from CAD collections which are now widely available. To alleviate the need for huge amounts of labeled data, we develop a rendering pipeline that enables synthesis of large datasets from a limited amount of manually labeled data. Using data thus synthesized, we learn category-level models for object deformations in 3D, as well as discriminative object features in 2D. These category models are instance-independent and aid in the design of object landmark observations that can be incorporated into a generic monocular SLAM framework. Where typical object-SLAM approaches usually solve only for object and camera poses, we also estimate object shape on-the-fly, allowing for a wide range of objects from the category to be present in the scene. Moreover, since our 2D object features are learned discriminatively, the proposed object-SLAM system succeeds in several scenarios where sparse feature-based monocular SLAM fails due to insufficient features or parallax. Also, the proposed category-models help in object instance retrieval, useful for Augmented Reality (AR) applications. We evaluate the proposed framework on multiple challenging real-world scenes and show — to the best of our knowledge — first results of an instance-independent monocular object-SLAM system and the benefits it enjoys over feature-based SLAM methods.
We present a monocular object SLAM system that uses category-level object representations as object observations
Parv implemented bulk of the object SLAM backend. Rishabh implemented the frontend. I proposed this project and mentored Parv and Rishabh, and wrote bulk of the manuscript.
@inproceedings{parkhiya2018icra, title = {Constructing Category-Specific Models for Monocular Object SLAM}, author = {Parkhiya, Parv and Khawad, Rishabh and Jatavallabhula, {Krishna Murthy} and K, {Madhava Krishna} and Bhowmick, Brojeshwar}, year = {2018}, booktitle = {ICRA}, }
2017
-
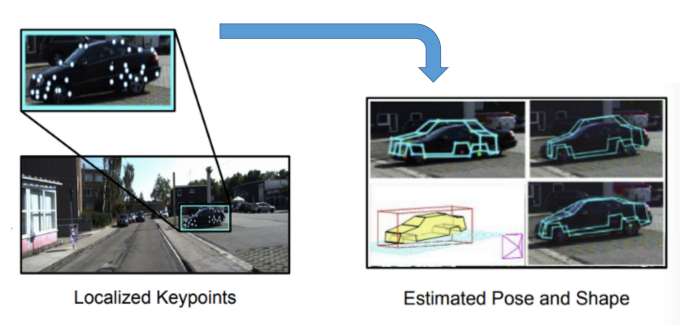
 Shape Priors for Real-Time Monocular Object Localization in Dynamic EnvironmentsKrishna Murthy Jatavallabhula, Sarthak Sharma, and Madhava Krishna KIROS 2017
Shape Priors for Real-Time Monocular Object Localization in Dynamic EnvironmentsKrishna Murthy Jatavallabhula, Sarthak Sharma, and Madhava Krishna KIROS 2017Reconstruction of dynamic objects in a scene is a highly challenging problem in the context of SLAM. In this paper, we present a real-time monocular object localization system that estimates the shape and pose of dynamic objects in real-time, using video frames captured from a moving monocular camera. Although the problem seems to be ill-posed, we demonstrate that, by incorporating prior knowledge of the object category, we can obtain more detailed instance-level reconstructions. As opposed to earlier object model specifications, the proposed shape-prior model leads to the formulation of a Bundle Adjustment-like optimization problem for simultaneous shape and pose estimation. Leveraging recent successes of Convolutional Neural Networks (CNNs) for object keypoint localization, we present a CNN architecture that performs precise keypoint localization. We then demonstrate how these keypoints can be used to recover 3D object properties, while accounting for any 2D localization errors and self-occlusion. We show significant performance improvements compared to state-of-the-art monocular competitors for 2D keypoint detection, as well as 3D localization and reconstruction of dynamic objects.
I did most of this work – part of my Masters thesis
@inproceedings{jatavallabhula2017iros, title = {Shape Priors for Real-Time Monocular Object Localization in Dynamic Environments}, author = {Jatavallabhula, {Krishna Murthy} and Sharma, Sarthak and K, {Madhava Krishna}}, year = {2017}, booktitle = {IROS}, } -
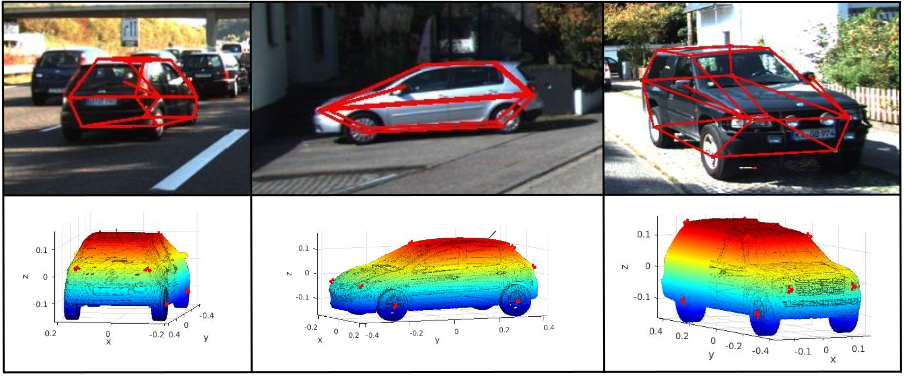 Reconstructing Vehicles From a Single Image: Shape Priors for Road Scene UnderstandingKrishna Murthy Jatavallabhula, Sai Krishna Gottipati, Falak Chhaya, and Madhava Krishna KICRA 2017
Reconstructing Vehicles From a Single Image: Shape Priors for Road Scene UnderstandingKrishna Murthy Jatavallabhula, Sai Krishna Gottipati, Falak Chhaya, and Madhava Krishna KICRA 2017We present an approach for reconstructing vehicles from a single (RGB) image, in the context of autonomous driving. Though the problem appears to be ill-posed, we demonstrate that prior knowledge about how 3D shapes of vehicles project to an image can be used to reason about the reverse process, i.e., how shapes (back-)project from 2D to 3D. We encode this knowledge in shape priors, which are learnt over a small keypoint-annotated dataset. We then formulate a shape-aware adjustment problem that uses the learnt shape priors to recover the 3D pose and shape of a query object from an image. For shape representation and inference, we leverage recent successes of Convolutional Neural Networks (CNNs) for the task of object and keypoint localization, and train a novel cascaded fully-convolutional architecture to localize vehicle keypoints in images. The shape-aware adjustment then robustly recovers shape (3D locations of the detected keypoints) while simultaneously filling in occluded keypoints. To tackle estimation errors incurred due to erroneously detected keypoints, we use an Iteratively Re-weighted Least Squares (IRLS) scheme for robust optimization, and as a by-product characterize noise models for each predicted keypoint. We evaluate our approach on autonomous driving benchmarks, and present superior results to existing monocular, as well as stereo approaches.
I did most of this work – part of my Masters thesis
@inproceedings{jatavallabhula2017icra, title = {Reconstructing Vehicles From a Single Image: Shape Priors for Road Scene Understanding}, author = {Jatavallabhula, {Krishna Murthy} and Gottipati, {Sai Krishna} and Chhaya, Falak and K, {Madhava Krishna}}, year = {2017}, booktitle = {ICRA}, }
2016
- JIRSFAST: Frontier Allocation Synchronized by Token-passingAvinash Gautam, Bhargav Jha, Gourav Kumar, Krishna Murthy Jatavallabhula, Arjun Ram S P, and Sudeept MohanSpringer Journal of Intelligent Robotic Systems 2016
We present an efficient, complete, and fault-tolerant multi-robot exploration algorithm
I designed and implemented the core algorithm. Authors listed lexicographically by their lastname (my lastname was assumed to be "Murthy") (except for the senior author; listed last)
@inproceedings{fast, title = {FAST: Frontier Allocation Synchronized by Token-passing}, author = {Gautam, Avinash and Jha, Bhargav and Kumar, Gourav and Jatavallabhula, {Krishna Murthy} and {S P}, {Arjun Ram} and Mohan, Sudeept}, year = {2016}, booktitle = {Springer Journal of Intelligent Robotic Systems}, }
2015
- SMCCluster, Allocate, Cover: An Efficient Approach for Multi-robot CoverageAvinash Gautam, Krishna Murthy Jatavallabhula, Gourav Kumar, Arjun Ram S P, Bhargav Jha, and Sudeept MohanIEEE SMC 2015
We design a performant online multi-robot coverage path planning technique
I designed and implemented core aspects of the algorithm
@inproceedings{cac, title = {Cluster, Allocate, Cover: An Efficient Approach for Multi-robot Coverage}, author = {Gautam, Avinash and Jatavallabhula, {Krishna Murthy} and Kumar, Gourav and {S P}, {Arjun Ram} and Jha, Bhargav and Mohan, Sudeept}, year = {2015}, booktitle = {IEEE SMC}, } - UKSIMMaxxyt: An Autonomous Wearable Device for Real-Time Tracking of a Wide Range of ExercisesDanish Pruthi, Ayush Jain, Krishna Murthy Jatavallabhula, and Puneet TejaUKSIM 2015
We design a wearable device capable of tracking exercise activty entirely on a low-resource microcontroller.
I prototyped a few algorithms for tracking and recording repetitions and helped write the manuscript
@inproceedings{maxxyt, title = {Maxxyt: An Autonomous Wearable Device for Real-Time Tracking of a Wide Range of Exercises}, author = {Pruthi, Danish and Jain, Ayush and Jatavallabhula, {Krishna Murthy} and Teja, Puneet}, year = {2015}, booktitle = {UKSIM}, }